|
| Alphazero : Stockfish battu 28 à 0 par le module de DeepMind par ins7708 le
[Aller à la fin] |
| Actualités | |
En 9h d'apprentissage, le programme de deep learning de Google a acquis une force surhumaine, et surmodulienne.
lien vers l'étude
Il a battu Stockfisch (3200 elo environ) 25 gains pour 25 nulles et 0 défaite avec les blancs et 3 gains pour 47 nulles et 0 défaite avec les noirs.
DeepMind avait déjà conquis le go et après le jeu d'échecs a également écrasé le shogi.
Quelques parties :
White: Stockfish Black: AlphaZero
1. e4 e5 2. Nf3 Nc6 3. Bb5 Nf6 4. d3 Bc5 5. Bxc6 dxc6 6. 0-0 Nd7 7. Nbd2 0-0 8. Qe1 f6 9. Nc4 Rf7
10. a4 Bf8 11. Kh1 Nc5 12. a5 Ne6 13. Ncxe5 fxe5 14. Nxe5 Rf6 15. Ng4 Rf7 16. Ne5 Re7 17. a6 c5
18. f4 Qe8 19. axb7 Bxb7 20. Qa5 Nd4 21. Qc3 Re6 22. Be3 Rb6 23. Nc4 Rb4 24. b3 a5 25. Rxa5
Rxa5 26. Nxa5 Ba6 27. Bxd4 Rxd4 28. Nc4 Rd8 29. g3 h6 30. Qa5 Bc8 31. Qxc7 Bh3 32. Rg1 Rd7
33. Qe5 Qxe5 34. Nxe5 Ra7 35. Nc4 g5 36. Rc1 Bg7 37. Ne5 Ra8 38. Nf3 Bb2 39. Rb1 Bc3 40. Ng1
Bd7 41. Ne2 Bd2 42. Rd1 Be3 43. Kg2 Bg4 44. Re1 Bd2 45. Rf1 Ra2 46. h3 Bxe2 47. Rf2 Bxf4 48.
Rxe2 Be5 49. Rf2 Kg7 50. g4 Bd4 51. Re2 Kf6 52. e5+ Bxe5 53. Kf3 Ra1 54. Rf2 Re1 55. Kg2+ Bf4
56. c3 Rc1 57. d4 Rxc3 58. dxc5 Rxc5 59. b4 Rc3 60. h4 Ke5 61. hxg5 hxg5 62. Re2+ Kf6 63. Kf2
Be5 64. Ra2 Rc4 65. Ra6+ Ke7 66. Ra5 Ke6 67. Ra6+ Bd6 0-1
White: Stockfish Black: AlphaZero
1. e4 e5 2. Nf3 Nc6 3. Bb5 Nf6 4. d3 Bc5 5. Bxc6 dxc6 6. 0-0 Nd7 7. c3 0-0 8. d4 Bd6 9. Bg5 Qe8 10.
Re1 f6 11. Bh4 Qf7 12. Nbd2 a5 13. Bg3 Re8 14. Qc2 Nf8 15. c4 c5 16. d5 b6 17. Nh4 g6 18. Nhf3
Bd7 19. Rad1 Re7 20. h3 Qg7 21. Qc3 Rae8 22. a3 h6 23. Bh4 Rf7 24. Bg3 Rfe7 25. Bh4 Rf7 26. Bg3
a4 27. Kh1 Rfe7 28. Bh4 Rf7 29. Bg3 Rfe7 30. Bh4 g5 31. Bg3 Ng6 32. Nf1 Rf7 33. Ne3 Ne7 34. Qd3
h5 35. h4 Nc8 36. Re2 g4 37. Nd2 Qh7 38. Kg1 Bf8 39. Nb1 Nd6 40. Nc3 Bh6 41. Rf1 Ra8 42. Kh2
Kf8 43. Kg1 Qg6 44. f4 gxf3 45. Rxf3 Bxe3+ 46. Rfxe3 Ke7 47. Be1 Qh7 48. Rg3 Rg7 49. Rxg7+
Qxg7 50. Re3 Rg8 51. Rg3 Qh8 52. Nb1 Rxg3 53. Bxg3 Qh6 54. Nd2 Bg4 55. Kh2 Kd7 56. b3 axb3
57. Nxb3 Qg6 58. Nd2 Bd1 59. Nf3 Ba4 60. Nd2 Ke7 61. Bf2 Qg4 62. Qf3 Bd1 63. Qxg4 Bxg4 64. a4
Nb7 65. Nb1 Na5 66. Be3 Nxc4 67. Bc1 Bd7 68. Nc3 c6 69. Kg1 cxd5 70. exd5 Bf5 71. Kf2 Nd6 72.
Be3 Ne4+ 73. Nxe4 Bxe4 74. a5 bxa5 75. Bxc5+ Kd7 76. d6 Bf5 77. Ba3 Kc6 78. Ke1 Kd5 79. Kd2
Ke4 80. Bb2 Kf4 81. Bc1 Kg3 82. Ke2 a4 83. Kf1 Kxh4 84. Kf2 Kg4 85. Ba3 Bd7 86. Bc1 Kf5 87.
Ke3 Ke6 0-1
White: AlphaZero Black: Stockfish
1. Nf3 Nf6 2. c4 b6 3. d4 e6 4. g3 Ba6 5. Qc2 c5 6. d5 exd5 7. cxd5 Bb7 8. Bg2 Nxd5 9. 0-0 Nc6 10.
Rd1 Be7 11. Qf5 Nf6 12. e4 g6 13. Qf4 0-0 14. e5 Nh5 15. Qg4 Re8 16. Nc3 Qb8 17. Nd5 Bf8 18.
Bf4 Qc8 19. h3 Ne7 20. Ne3 Bc6 21. Rd6 Ng7 22. Rf6 Qb7 23. Bh6 Nd5 24. Nxd5 Bxd5 25. Rd1 Ne6
26. Bxf8 Rxf8 27. Qh4 Bc6 28. Qh6 Rae8 29. Rd6 Bxf3 30. Bxf3 Qa6 31. h4 Qa5 32. Rd1 c4 33. Rd5
Qe1+ 34. Kg2 c3 35. bxc3 Qxc3 36. h5 Re7 37. Bd1 Qe1 38. Bb3 Rd8 39. Rf3 Qe4 40. Qd2 Qg4 41.
Bd1 Qe4 42. h6 Nc7 43. Rd6 Ne6 44. Bb3 Qxe5 45. Rd5 Qh8 46. Qb4 Nc5 47. Rxc5 bxc5 48. Qh4
Rde8 49. Rf6 Rf8 50. Qf4 a5 51. g4 d5 52. Bxd5 Rd7 53. Bc4 a4 54. g5 a3 55. Qf3 Rc7 56. Qxa3 Qxf6
57. gxf6 Rfc8 58. Qd3 Rf8 59. Qd6 Rfc8 60. a4 1-0
16
White: AlphaZero Black: Stockfish
1. d4 e6 2. Nc3 Nf6 3. e4 d5 4. e5 Nfd7 5. f4 c5 6. Nf3 Nc6 7. Be3 Be7 8. Qd2 a6 9. Bd3 c4 10. Be2 b5
11. a3 Rb8 12. 0-0 0-0 13. f5 a5 14. fxe6 fxe6 15. Bd1 b4 16. axb4 axb4 17. Ne2 c3 18. bxc3 Nb6 19.
Qe1 Nc4 20. Bc1 bxc3 21. Qxc3 Qb6 22. Kh1 Nb2 23. Nf4 Nxd1 24. Rxd1 Bd7 25. h4 Ra8 26. Bd2
Rfb8 27. h5 Rxa1 28. Rxa1 Qb2 29. Qxb2 Rxb2 30. c3 Rb3 31. Ra8+ Rb8 32. Ra2 Rb3 33. g4 Ra3 34.
Rb2 Kf7 35. Kg2 Bc8 36. Rb6 Ra6 37. Rb1 Ke8 38. Kg3 h6 39. Ng6 Ra3 40. Rb6 Bd7 41. g5 hxg5 42.
Kg4 Bd8 43. Rb2 Bc8 44. Nxg5 Ra1 45. Nf3 Ra3 46. Be1 Ba5 47. Rf2 Ra1 48. Bd2 Bd8 49. Rh2 Ne7
50. Bg5 Nf5 51. Bxd8 Kxd8 52. Rb2 Rc1 53. Ngh4 Nxh4 54. Nxh4 Bd7 55. Rb8+ Bc8 56. Ng2 Rxc3
57. Nf4 Rc1 58. Ra8 Kd7 59. Kf3 Rc3+ 60. Kf2 Ke7 61. Kg2 Kf7 62. Ng6 Ke8 63. Ra1 Rc7 64. Kh3
Rf7 65. Kg4 Kd8 66. Nf4 Bd7 67. Ra7 Kc8 68. Kg3 Re7 69. Nd3 Kb8 70. Ra6 Bc8 71. Rb6+ Kc7 72.
Rd6 Kb8 73. Nc5 g6 74. h6 Rh7 75. Nxe6 Rxh6 76. Nf4 Rh1 77. Nxd5 Rh3+ 78. Kf4 Rh4+ 79. Ke3
Rh3+ 80. Kd2 Bf5 81. Ne7 Rh2+ 82. Ke3 Bh3 83. Nxg6 Rh1 84. Nf4 Bg4 85. Rf6 Kc7 86. Nd3 Bd7
87. d5 Bb5 88. Nf4 Ba4 89. Kd4 Be8 90. Rf8 Rd1+ 91. Kc5 Rc1+ 92. Kb4 Rb1+ 93. Kc3 Bb5 94. Kd4
Ba6 95. Rf7+ 1-0
White: AlphaZero Black: Stockfish
1. d4 Nf6 2. c4 e6 3. Nf3 b6 4. g3 Bb7 5. Bg2 Be7 6. 0-0 0-0 7. d5 exd5 8. Nh4 c6 9. cxd5 Nxd5 10.
Nf5 Nc7 11. e4 Bf6 12. Nd6 Ba6 13. Re1 Ne8 14. e5 Nxd6 15. exf6 Qxf6 16. Nc3 Nb7 17. Ne4 Qg6
18. h4 h6 19. h5 Qh7 20. Qg4 Kh8 21. Bg5 f5 22. Qf4 Nc5 23. Be7 Nd3 24. Qd6 Nxe1 25. Rxe1 fxe4
26. Bxe4 Rf5 27. Bh4 Bc4 28. g4 Rd5 29. Bxd5 Bxd5 30. Re8+ Bg8 31. Bg3 c5 32. Qd5 d6 33. Qxa8
Nd7 34. Qe4 Nf6 35. Qxh7+ Kxh7 36. Re7 Nxg4 37. Rxa7 Nf6 38. Bxd6 Be6 39. Be5 Nd7 40. Bc3 g6
41. Bd2 gxh5 42. a3 Kg6 43. Bf4 Kf5 44. Bc7 h4 45. Ra8 h5 46. Rh8 Kg6 47. Rd8 Kf7 48. f3 Bf5 49.
Bh2 h3 50. Rh8 Kg6 51. Re8 Kf7 52. Re1 Be6 53. Bc7 b5 54. Kh2 Kf6 55. Re3 Ke7 56. Re4 Kf7 57.
Bd6 Kf6 58. Kg3 Kf7 59. Kf2 Bf5 60. Re1 Kg6 61. Kg1 c4 62. Kh2 h4 63. Be7 Nb6 64. Bxh4 Na4 65.
Re2 Nc5 66. Re5 Nb3 67. Rd5 Be6 68. Rd6 Kf5 69. Be1 Ke5 70. Rb6 Bd7 71. Kg3 Nc1 72. Rh6 Kd5
73. Bc3 Bf5 74. Rh5 Ke6 75. Kf2 Nd3+ 76. Kg1 Nf4 77. Rh6+ Ke7 78. Kh2 Nd5 79. Kg3 Be6 80. Rh5
Ke8 81. Re5 Kf7 82. Bd2 Ne7 83. Bb4 Nd5 84. Bc3 Ke7 85. Bd2 Kf6 86. f4 Ne7 87. Rxb5 Nf5+ 88.
Kh2 Ke7 89. Ra5 Nh4 90. Bb4+ Kf7 91. Rh5 Nf3+ 92. Kg3 Kg6 93. Rh8 Nd4 94. Bc3 Nf5+ 95. Kxh3
Bd7 96. Kh2 Kf7 97. Rb8 Ke6 98. Kg1 Bc6 99. Rb6 Kd5 100. Kf2 Bd7 101. Ke1 Ke4 102. Bd2 Kd5
103. Rf6 Nd6 104. Rh6 Nf5 105. Rh8 Ke4 106. Rh7 Bc8 107. Rc7 Ba6 108. Rc6 Bb5 109. Rc5 Bd7
110. Rxc4+ Kd5 111. Rc7 Kd6 112. Rc3 Ke6 113. Rc5 Nd4 114. Be3 Nf5 115. Bf2 Nd6 116. Rc3 Ne4
117. Rd3 1-0
White: AlphaZero Black: Stockfish
1. d4 Nf6 2. Nf3 e6 3. c4 b6 4. g3 Be7 5. Bg2 Bb7 6. 0-0 0-0 7. d5 exd5 8. Nh4 c6 9. cxd5 Nxd5 10.
Nf5 Nc7 11. e4 Bf6 12. Nd6 Ba6 13. Re1 Ne8 14. e5 Nxd6 15. exf6 Qxf6 16. Nc3 Bc4 17. h4 h6 18.
b3 Qxc3 19. Bf4 Nb7 20. bxc4 Qf6 21. Be4 Na6 22. Be5 Qe6 23. Bd3 f6 24. Bd4 Qf7 25. Qg4 Rfd8
26. Re3 Nac5 27. Bg6 Qf8 28. Rd1 Rab8 29. Kg2 Ne6 30. Bc3 Nbc5 31. Rde1 Na4 32. Bd2 Kh8 33.
f4 Qd6 34. Bc1 Nd4 35. Re7 f5 36. Bxf5 Nxf5 37. Qxf5 Rf8 38. Rxd7 Rxf5 39. Rxd6 Rf7 40. g4 Kg8
41. g5 hxg5 42. hxg5 Nc5 43. Kf3 Nb7 44. Rdd1 Na5 45. Re4 c5 46. Bb2 Nc6 47. g6 Rc7 48. Kg4
Nd4 49. Rd2 Rf8 50. Bxd4 cxd4 51. Rdxd4 Rfc8 52. Kg5 Rf8 53. Rd2 Rc6 54. Rd5 Rc7 55. f5 Rb7 56.
a3 Rc7 57. a4 a6 58. Red4 Rcc8 59. Re5 Rc7 60. a5 Rc5 61. Rxc5 bxc5 62. Rd6 Ra8 63. Re6 Kf8 64.
Rc6 Ke7 65. Kf4 Kd7 66. Rxc5 Rh8 67. Rd5+ Ke7 68. Re5+ Kd7 69. Re6 Rh4+ 70. Kg5 1-0
17
White: AlphaZero Black: Stockfish
1. d4 Nf6 2. c4 e6 3. Nf3 b6 4. g3 Bb7 5. Bg2 Bb4+ 6. Bd2 Bxd2+ 7. Qxd2 d5 8. 0-0 0-0 9. cxd5 exd5
10. Nc3 Nbd7 11. b4 c6 12. Qb2 a5 13. b5 c5 14. Rac1 Qe7 15. Na4 Rab8 16. Rfd1 c4 17. Ne5 Qe6
18. f4 Rfd8 19. Qd2 Nf8 20. Nc3 Ng6 21. Rf1 Qd6 22. a4 Rbc8 23. e3 Ne7 24. g4 Ne8 25. f5 f6 26.
Nf3 Qd7 27. Qf2 Nd6 28. Nd2 Rf8 29. Qg3 Rcd8 30. Rf4 Nf7 31. Rf2 Rfe8 32. h3 Qd6 33. Nf1 Qa3
34. Rcc2 h5 35. Qc7 Qd6 36. Qxd6 Rxd6 37. Ng3 h4 38. Nh5 Ng5 39. Rf1 Kh7 40. Nf4 Rdd8 41. Kh2
Rd7 42. Bh1 Rd6 43. Ng2 g6 44. Nxh4 gxf5 45. gxf5 Rh8 46. Nf3 Kg7 47. Nxg5 fxg5 48. Rg2 Kf6 49.
Rg3 Re8 50. Bf3 Rdd8 51. Be2 Rf8 52. Bg4 Nc8 53. Bf3 Rfe8 54. h4 Rh8 55. h5 Rhe8 56. Bg2 Ne7
57. h6 Rh8 58. Rh3 Rh7 59. Kg1 Ba8 60. Nd1 g4 61. Rh5 g3 62. Nc3 Ng8 63. Ne2 Rxh6 64. Nxg3
Rxh5 65. Nxh5+ Kf7 66. Kf2 Nf6 67. Nxf6 Kxf6 68. Rh1 c3 69. Rc1 Rh8 70. Rxc3 Kxf5 71. Rc7 Kf6
72. Bf3 Rg8 73. Rh7 Rg6 74. Bd1 Rg8 75. Rh6+ Ke7 76. Rxb6 Kd7 77. Rf6 Ke7 78. Rh6 Rg7 79. Rh8
Bb7 80. Rh5 Kd6 81. Rh3 Rf7+ 82. Ke1 Bc8 83. Rh6+ Kc7 84. Rc6+ Kb8 85. Rd6 Bb7 86. b6 Ba6 87.
Rxd5 Rf6 88. Rxa5 Rxb6 89. Kd2 Bb7 90. Rb5 Rf6 91. Bb3 Kc7 92. Re5 Ba6 93. Kc3 Rf1 94. Bc2
Rh1 95. a5 Kd6 96. e4 Bf1 97. Rf5 Bg2 98. Rf4 Rc1 99. Kb2 Rh1 100. a6 1-0
White: AlphaZero Black: Stockfish
1. d4 Nf6 2. c4 e6 3. Nf3 b6 4. g3 Bb7 5. Bg2 Bb4+ 6. Bd2 Be7 7. Nc3 c6 8. e4 d5 9. e5 Ne4 10. 0-0
Ba6 11. b3 Nxc3 12. Bxc3 dxc4 13. b4 b5 14. Nd2 0-0 15. Ne4 Bb7 16. Qg4 Nd7 17. Nc5 Nxc5 18.
dxc5 a5 19. a3 axb4 20. axb4 Rxa1 21. Rxa1 Qd3 22. Rc1 Ra8 23. h4 Qd8 24. Be4 Qc8 25. Kg2 Qc7
26. Qh5 g6 27. Qg4 Bf8 28. h5 Rd8 29. Qh4 Qe7 30. Qf6 Qe8 31. Rh1 Rd7 32. hxg6 fxg6 33. Qh4
Qe7 34. Qg4 Rd8 35. Bb2 Qf7 36. Bc1 c3 37. Be3 Be7 38. Qe2 Bf8 39. Qc2 Bg7 40. Qxc3 Qd7 41.
Rc1 Qc7 42. Bg5 Rf8 43. f4 h6 44. Bf6 Bxf6 45. exf6 Qf7 46. Ra1 Qxf6 47. Qxf6 Rxf6 48. Ra7 Rf7
49. Bxg6 Rd7 50. Kf2 Kf8 51. g4 Bc8 52. Ra8 Rc7 53. Ke3 h5 54. gxh5 Kg7 55. Ra2 Re7 56. Be4 e5
57. Bxc6 exf4+ 58. Kxf4 Rf7+ 59. Ke5 Rf5+ 60. Kd6 Rxh5 61. Rg2+ Kf6 62. Kc7 Bf5 63. Kb6 Rh4
64. Ka5 Bg4 65. Bxb5 Ke7 66. Rg3 Bc8 67. Re3+ Kf7 68. Be2 1-0
White: AlphaZero, Black: Stockfish
1. d4 e6 2. e4 d5 3. Nc3 Nf6 4. e5 Nfd7 5. f4 c5 6. Nf3 cxd4 7. Nb5 Bb4+ 8. Bd2 Bc5 9. b4 Be7 10.
Nbxd4 Nc6 11. c3 a5 12. b5 Nxd4 13. cxd4 Nb6 14. a4 Nc4 15. Bd3 Nxd2 16. Kxd2 Bd7 17. Ke3 b6
18. g4 h5 19. Qg1 hxg4 20. Qxg4 Bf8 21. h4 Qe7 22. Rhc1 g6 23. Rc2 Kd8 24. Rac1 Qe8 25. Rc7 Rc8
26. Rxc8+ Bxc8 27. Rc6 Bb7 28. Rc2 Kd7 29. Ng5 Be7 30. Bxg6 Bxg5 31. Qxg5 fxg6 32. f5 Rg8 33.
Qh6 Qf7 34. f6 Kd8 35. Kd2 Kd7 36. Rc1 Kd8 37. Qe3 Qf8 38. Qc3 Qb4 39. Qxb4 axb4 40. Rg1 b3
41. Kc3 Bc8 42. Kxb3 Bd7 43. Kb4 Be8 44. Ra1 Kc7 45. a5 Bd7 46. axb6+ Kxb6 47. Ra6+ Kb7 48.
Kc5 Rd8 49. Ra2 Rc8+ 50. Kd6 Be8 51. Ke7 g5 52. hxg5 1-0
White: AlphaZero, Black: Stockfish
1. Nf3 Nf6 2. d4 e6 3. c4 b6 4. g3 Bb7 5. Bg2 Be7 6. 0-0 0-0 7. d5 exd5 8. Nh4 c6 9. cxd5 Nxd5 10.
Nf5 Nc7 11. e4 d5 12. exd5 Nxd5 13. Nc3 Nxc3 14. Qg4 g6 15. Nh6+ Kg7 16. bxc3 Bc8 17. Qf4 Qd6
18. Qa4 g5 19. Re1 Kxh6 20. h4 f6 21. Be3 Bf5 22. Rad1 Qa3 23. Qc4 b5 24. hxg5+ fxg5 25. Qh4+
Kg6 26. Qh1 Kg7 27. Be4 Bg6 28. Bxg6 hxg6 29. Qh3 Bf6 30. Kg2 Qxa2 31. Rh1 Qg8 32. c4 Re8 33.
Bd4 Bxd4 34. Rxd4 Rd8 35. Rxd8 Qxd8 36. Qe6 Nd7 37. Rd1 Nc5 38. Rxd8 Nxe6 39. Rxa8 Kf6 40.
cxb5 cxb5 41. Kf3 Nd4+ 42. Ke4 Nc6 43. Rc8 Ne7 44. Rb8 Nf5 45. g4 Nh6 46. f3 Nf7 47. Ra8 Nd6+
48. Kd5 Nc4 49. Rxa7 Ne3+ 50. Ke4 Nc4 51. Ra6+ Kg7 52. Rc6 Kf7 53. Rc5 Ke6 54. Rxg5 Kf6 55.
Rc5 g5 56. Kd4 1-0
|
|
|
Pour ceux qui n'avait pas suivi l'exploit de la dernière version d'AlphaGo, précisons que Deep Mind est parti de rien d'autre que les règles de jeu, et a appris tout seul, en jouant contre lui même. Pendant 9h.
Notons que AlphaZero, qui se base sur le reconnaissance de patterns caractéristique du deep learning calcule 9 fois moins vite que stockfish (seulement 70 000 positions / secondes). Ce n'est donc pas une victoire de la force brute à la deep blue, mais d'une intelligence artificielle proche de l'intelligence humaine.
La cadence du match en 100 parties était de 1 min par coup. Et le score hallucinant de 28 à 0, 72 nulles.
Durant son apprentissage AlphaZero a redécouvert toutes les grandes ouvertures humaines, préférant certaines avant de les délaisser.
Les 4 ouvertures les plus jouées par lui sont
1. l'Anglaise 1.c4
2. le gambit dame 1.d4 d5 2.c4
3. 1. d4 Cf6 2.Cf3
4. 1.d4 Cf6 2.c4 e6
|
|
|
Wow ça c'est la révolution! Si ça se passe comme au go... je me demandais justement si c'était prévu une forme "alphachess" mais google semblait ne pas montrer d'intérêt.
|
|
|
Si ce genre de module venait a être commercialisé de manière accessible ne serait ce que pour une poignée de joueurs on peut craindre la "résolution de notre jeu" et un phénomène de préparation encore plus important. Ça stéréotyperait encore plus le jeu à haut niveau c est triste.
|
|
|
Au poker à deux joueurs, l'ordi est imbattable.
Les Alphas (go, chess, shogi) doivent s'approcher du jeu parfait.
Je pensais que un AlphaChess était impossible, j'étais bien naïf. En 9h, Google a (quasi) résolu les échecs. (On est loin d'une résolution parfaite des tablebases 32, mais je suis pas sûr que Caissa prenne beaucoup de parties à AlphaZero.)
|
|
|
C est a la fois intéressant pour approfondir les subtilités du jeu et inquiétant pour l avenir du jeu en lui même
|
|
|
Il faut espérer que Deep Mind distribue tout gratuitement. Si un seul joueur du top achète en sous main AlphaZero, il aurait un edge énorme.
Pour nous autres, cela ne changera rien ou pas grand chose.
|
|
|
C'est hallucinant cette nouvelle, hallucinant.
A mon avis ça va encore avoir un impact de folie sur le jeu de top niveau...
L'ordinateur apprendra à quelques heures à jouer parfaitement une ouverture qu'on peine à jouer depuis des centaines d'années ?
Ou alors démontrera t'on que plein de systèmes sont bien "jouables" ?
|
|
|
Nom de Zeus !
A noter qu'aux environs de la deuxième heure d'apprentissage, il a "kiffé grave" la Défense Française, Alphazoro... Avant de trouver ça complétement naze.
|
|
|
La 9eme partie du papier est sympa avec Rxd2 et Rxe3. Il semble super humain comme module.
|
|
|
Cette étude est absolument fascinante! Ce qui est en particulier bluffant, c'est l'évolution "historique" des choix d'ouverture dans le processus d'apprentissage. On pourrait presque y lire une similitude avec la pratique à haut niveau de ces dernières décennies.
Par contre, il leur faudrait peut-être un coup de main d'un joueur d'échecs qualifié pour présenter leurs résultats. Les codes ECO correspondent aux positions présentées, mais les suites en-dessous (plus longues) transposent dans d'autres ouvertures : typiquement, ce qu'ils nomment "King's Indian Defence" correspond à la Grunfeld. Aussi, ce serait intéressant (pour nous) de différencier les choix par couleur : sous cette forme, les graphiques ne permettent pas de déterminer laquelle des 2 raisons expliquent qu'à un moment t, la française devient moins populaire :
- est-ce parce que les blancs se mettent à jouer autre que 1.e4 ? Auquel cas, ça voudrait dire que la française est considérée à cet instant t une bonne ouverture pour les noirs
- est-ce parce que les noirs jouent autre chose sur 1.e4? Conclusion inverse
|
|
|
J'ai tendance à me méfier de ce que je ne comprends pas.
Je pensais que pour le go, cette image de l'auto-apprentissage était une sorte d'image naïve pour journalistes.
Mais j'avais peut-être tort ?!
Je ne comprends pas comment le logiciel arrive à "mémoriser" de ses erreurs.Si c'était vraiment possible la vitesse serait remplacée par la mémoire il me semble....mais alors il faudrait un espace de stockage colossal.
Si quelqu'un pouvait éclairer ma (faible) lanterne ;o)
|
|
|
Effectivement c'est une grosse nouvelle, même si c'était prévisible depuis AlphaGO.
J'imagine que sur ce forum il doit y avoir quelques connaisseurs du machine learning, si quelqu'un pouvait expliquer grossièrement le fonctionnement de la chose... Je comprends pas, même après 2 lectures de l'article. Je les trouve un peu radins en explication, même si c'est bien sûr un article de recherche et pas un article de vulgarisation.
Ce que je comprends (grossièrement) :
-l'ordinateur joue contre lui même comme un peintre, en jouant juste des coups légaux. A chaque itération (nouvelle partie), l'ordinateur joue comme (c'est à dire?) sa "meilleure version", pour s'améliorer d'itération en itération.
Visiblement le processus de sélection des coups est basé sur des méthodes de MonteCarlo (Monte Carlo Tree Search), sauf qu'en lisant l'article de Wikipédia j'ai l'impression que le principe du MCTS c'est basé sur plein de simulations successives pour choisir finalement le "noeud" qui a la meilleure espérance de gain (en quelque sorte). Sauf qu'aux échecs c'est impossible de tout simuler par la force brute, donc j'imagine que ce MCTS est "couplé" à des méthodes de reconnaissances de patterns comme le dit Petiteglise mais j'ai quand même du mal à comprendre concrètement comment en un si "petit" nombre de parties (44 millions) l'ordinateur a pu exploré suffisament de fausses pistes et a engrangé suffisament d'expérience pour avoir une vue claire des probabilités de chaque "noeud" en fonction des "patterns" qui se dégagent..
C'est vraiment obscur pour moi, si quelqu'un peut aider...
|
|
|
On peut supposer que le module de lui même tend à comprendre quelle ouverture lui donne le plus de chance de gagner...!
|
|
|
@Adrct
Je partage pleinement votre interrogation.
|
|
|
AlphaZero a une fonction de calcul donc même au début de son apprentissage s'il y a un mat en 3 il le voit. Et surtout une fonction de reconnaissance de patterns. Au début il joue au hasard et quand il gagne il "comprend" que le pattern de la position finale ressemble à une position gagnante. En jouant des millions de parties il obtient des millions de patterns qui ressemblent soit à une position gagnante soit nulle. Quand il joue il calcule et joue le coup qui amène une position "ressemblant le plus possible à un pattern gagnant".
C'est en fait ce que nous humains faisons.
(Sauf qu'on apprend nos patterns en regardant des parties de gm, pas en jouant tout seul).
Voilà le très bref résumé. Après seuls les génies de Google comprennent les détails de DeepMind.
|
|
|
Concernant le machine learning, je recommande la leçon inaugurale au Collège de France de Yann Le Cun (https://www.college-de-france.fr/site/yann-lecun/inaugural-lecture-2016-02-04-18h00.htm). Ça dure environ 2 heures et c'est très abordable. En ce qui me concerne, ça a largement dissipé le caractère "magique" de ce type de méthodes!
|
|
|
Il y a beaucoup + de détails dans l'article sur AlphaGo, disponible en téléchargement sur cette page http://www.gmelli.org/RKB/Self-Play_Reinforcement_Learning_Algorithm ( “Mastering the Game of Go Without Human Knowledge", 2017).
Je tente d'en comprendre davantage ! Effectivement durruti je ne pense pas que cela soit "si" complexe.
|
|
|
Commentaire d'Alphazero après sa première partie contre lui-même : "Ah que zéro-zéro !"
|
|
|
En fait le 44 millions de parties est réducteur, à chaque partie il fait, si je comprends bien, 1600 "fin de parties" à partir de la position en cours chaque fois qu'il doit choisir un coup, et il utilise le résultat de ces simulations pour se renforcer (et pour choisir le coup à jouer, ou plutôt une probabilité de jouer chaque coup, histoire d'explorer quand même de temps en temps des coups qu'il juge moins bons à ce stade de son apprentissage).
On est plus proche du millier de milliards de parties simulées.
|
|
|
C'était une question de temps, Google sait recruter.
Maintenant Alpha n'en gagne que 3 sur 50 avec les noirs...
Combien de nulles quand il se joue lui-même ?
|
|
|
Les réseaux de neurones existaient déjà il y a 50 ans et on pressentait leur efficacité potentielle, mais la puissance de calcul manquait. Il n'y a pas grand chose de si extraordinairement nouveau d'un point de vue conceptuel aujourd'hui. La nouveauté principale est qu'on arrive à faire fonctionner des réseaux beaucoup plus grands (avec un grand nombre de couches de neurones d'où le "deep"), permettant de simuler des fonctions de plus en plus complexes. Ce qui permet par exemple d'associer à une position donnée du jeu d'échecs une valeur plus précise.
|
|
|
On notera que AlphaZero joue la berlinoise (cf les deux premières parties) et ne joue plus 1.e4 (à cause de la berlinoise? ) mais essentiellement d4 et c4.
Qui doutait encore du génie de Kramnik ?
|
|
|
Topalov ;-)
|
|
|
On peut être fiers d'avoir compris tout seuls que 3...a6 n'était pas terrible !
Perso j'ai joué la berlinoise avant Kramnik en regardant des parties d'Alexandrov.
|
|
|
Le papier sur les échecs est bien moins détaillé que celui du go, c'est frustrant !
Par exemple, un truc très intéressant concernant AlphaGo :
ils ont développé 2 programmes ; l'un, auquel ils n'ont appris que les règles du jeu.
L'autre, auxquels ils ont aussi ajouté des "apriori" d'experts (un peu comme pour les programmes classiques, même si là c'est juste pour influencer ses simulations, en gros pour changer les probabilité a priori attribué au programme pour chaque coup).
Au départ, le programme qui part de rien galère bien sûr, mais au bout d'un nombre suffisant de parties jouées il devient meilleur que celui qui est freiné dans son apprentissage par des apriori.
Mais ce n'est pas le plus intéressant :
Le programme auquel on apprend des apriori reste, même après un très grand nombre de simulations, plus performant pour prédire un coup joué par un professionnel à partir d'une position issue d'une partie réelle, que celui qui a appris à jouer tout seul.
En d'autres terme, paradoxalement, ce sont les programmes actuels qui ont tendance à continuer un peu à "jouer comme des humains" (car on leur inculque nos propres critères d'évaluation), mais alphaGO a lui en quelque sorte fait progresser la science du go, puisqu'il ne joue plus comme un humain, il a un style réellement différent.
Je me demande si on retrouve la même chose pour les échecs, c'est à dire si on pourra se rendre compte en analysant de nombreuses parties d'AlphaZero qu'il a "trouvé" des considérations stratégiques inconnues des humains jusqu'alors, et donc non contenues dans les critères que l'on inculque aux programmes d'échecs actuels.
J'espère ne pas dire trop de bêtises, je me fie a ce que je lis sur leurs articles mais je comprends peut être des choses de travers !
|
|
|
@Adrct, ce n'est pas le papier complet. Demis Hassabis (le CEO de Deepmind) a commenté aujourd'hui sur Twitter "no opening book, no endgame database, no heuristics, no nothing! full paper coming soon, will have things like early games."
|
|
|
@Adrct : des quelques parties publiées que j'ai vues, les conceptions d'AlphaZero m'ont semblé assez révolutionnaires. Stockfish n'a pas réussi à prévoir certaines de ces conceptions, ou en tout cas à en prévoir la force.
|
|
|
Ok merci MChoiz, attendons alors !
Ca risque de faire parler cette histoire !
|
|
|
Intéressant de noter que contrairement aux échecs, jouer avec l'autre couleur au go ou shogi ne change pas trop sa performance! A croire que le trait au go ou shogi serait moins avantageux qu'aux échecs (semblant pourtant déjà si bas avant la raclée donnée par Alphachess mais montrant qu'avec les Noirs tout va bien!).
|
|
|
Complexes ces parties, et dans un sens c'est rassurant puisqu'un être humain ne pourra pas maîtriser tout ça. C'est bien beau de jouer les coups de l'ordi mais les joueurs trouveront-ils les coups de l'ordi pour réfuter l'adversaire ? Rien de moins sûr.
Soyons optimiste, ça va peut être réfuter des ouvertures mais ça va aussi ouvrir de nouvelles voies.
|
|
|
Le plus intéressant est de savoir ce qui se passe quand il se joue lui-même.
Gagne-t-il parfois avec les noirs ? combien avec les blancs ?
|
|
|
ok mais vous ne pensez pas qu'AlphaZéro a déjà atteint ses limites ?
|
|
|
et surtout, malgré la tôle que prend Stockfish, ça ne fait même pas 100 points elo d'écart. Comme quoi le jeu parfait doit pas dépasser 3500 elo (même s'il y a des subtilités car ce n'est pas forcément le jeu parfait qui rapporte le plus contre des adversaires imparfaits).
|
|
|
@elkine : 99.9% de nulles. Environ.
|
|
|
On n'a pas fini d'en voir des berlinoises...
|
|
|
c'est bien ce que je pensais... comme à Londres bien que l'aversion au risque soit différente
|
|
|
Apparement d4 c4 g3 Bg2 est LE meilleur plan aux échecs avec les blancs. e4 refuté par la berlinoise.
La theorie des ouvertures, milieu de jeu et finales vient d'être plié par Google. On n'aura plus qu'à brancher Alphazero pour avoir le ou les coups parfaits sur chaque position.
|
|
|
Ce qui est marrant aussi je trouve c'est que l'ordinateur soit lui même passé d'ouvertures risqués à des ouvertures plus solide au fil des années, un peu comme fond les hommes en devenant vieux :-) !
|
|
|
Les parties sont extraordinaires. AlphaZero a un sens du dynamisme incroyable, sacrifiant souvent un puis deux pions pour des compensations positionnelles à long terme.
Un exemple parmi les autres :

|
|
|
après avoir gambité un pion dans l'ouverture puis sacrifié un deuxième, AlphaZero place Txc5!! bxc5 Dh4! Tde8 Tf6! Tf8 Df4!
et Stockfisch, malgré qualité et deux pions de plus, est humilié.

|
|
|
je ne sais pas si Stockfish connaitra un jour le sentiment d'humiliation ...
mais les 2 !! sont un minimum
|
|
|
C'est effrayant, bientôt l'intelligence humaine sera celle d'une amibe, comparativement aux AI...
Et déprimant pour les Echecs classiques, comme je le disais sur un autre fil, il va être urgent de passer au 960...
|
|
|
C'est celle que j'ai le plus aimée avec celle de Rxd2 Re3 et Fxg6 positionnel de folie.
Ce qui est marrant c'est de regarder les évaluations de Stockfish en rejouant les parties. Il comprend pas.
|
|
|
Même s'il est (très) bien mis en scène, ce résultat est une prouesse technologique avant d'être une prouesse scientifique. Comme AlphaGo en son temps, c'est avant tout une grosse débauche de temps de calcul et de moyens humains colossaux.
"9h d'apprentissage" c'est très vendeur mais ça ne veut rien dire en soit. D'une part cela ne comprend pas le temps de développement et surtout ce n'est pas 9h de calcul d'une brouette avec deux cœurs et 1gb de RAM. On a derrière une grosse puissance de feu de Google. Selon l'article il s'agit de 4 TPU ce qui correspondrait à une puissance cumulée de 720 teraflops. En gros, en occultant le fait que la mémoire vive ne suivrait probablement, on a un an de calcul sur la plus grosse bête de course du marché.
On a donc bien à faire de la force brute (désolé PE): un résultat fondé sur un très très grand nombre d'essais-erreurs et sur une importante dépense de ressources de calcul (les millions de parties jouées pour l'apprentissage). Cette dépense étant en partie réduite par une optimisation de l'exploration de l'arbre des variantes (le fameux Monte Carlo Tree Search).
En fait, ici ce qui a été résolu c'est avant tout un problème de calcul
Les réseaux de neurones peuvent apparaître comme une simulation de l'esprit humain à certains égards, cela n'en fait pas d'Alphazero une Intelligence Artificielle au sens strict du terme.
C'est un système très lourd, très spécialisé et incapable (à ce stade en tout cas) de créer de la connaissance, en somme une IA faible. Comme avec AlphaGo, on a une machine très performante mais qui ne "comprend" pas ce qu'elle produit et qui, pour autant que l'on sache, n'est pas capable non plus de synthétiser ses connaissances. A la question "Pourquoi 24.e3", Alphazero répondra "Parce que 49.Txa8".
S'il y a connaissance extraite, elle le sera par l'humain (comme dans les positions très intéressantes proposées ci-dessus). Ce qui serait une vraie avancée à mon sens ce serait de voir un programme partant de zéro et dont on puisse dire: tiens il a découvert l'opposition et il peut montrer à quoi ça sert.
|
|
|
Bon sang rien que la première je trouve ça génial, pour activer ses deux fous alphachess donne deux pions de plus et se retrouve avec une pièce pour 4 pions, et sur le coup 35.Tc1 que stockfish semble prévoir d'abord, il donne encore un pion en jouant 35...c4!! 36.Ccc4 Fc5 et le roi blanc reste coincé et mlagré les 5 pions pour la pièce la position est indéfendable... Vraiment très humain et superbe comme coup :).
La position après 35.Tc1 c4 36.Cxc4 Fc5 37.Cb2? Ta2 38.Cd1 Fd4 est amusante, totalement saucissoné le stockfish, on dirait une partie contre Capablanca :).
Et ça justifie le 30...Fc8 auparavant...
|
|
|
Et l'alternative 37.c3 Ff2 38.Cb2 Ta2 39.Tb1 Fe3 n'est pas mieux, les noirs n'ont plus qu'à ramener leur roi via f7 g6 h5 etc.. Malrgé leur marée de pions les blancs ne peuvent rien faire :).
|
|
|
@Meikuleilu : la puissance de calcul n'a été nécessaire que pour la création de l'IA. Mais est-ce beaucoup en comparaison des décennies de réflexion de centaines de programmeurs pour arriver à l'algo de Stockfish ?
Ensuite dans le match, Stockfish calculait 9 fois plus que AlphaZero.
Oui sig, l'idée c4 est magnifique !
|
|
|
"Stockfish calculait 9 fois plus que AlphaZero"
Mais calculait une énorme proportion de bêtises.
D'ailleurs il était à 400 ELO de plus, environ, que le meilleur humain actuel. Vu la proportion des capacités de calcul, l'écart devrait être plus important, mais voilà, le GM humain sélectionne quelques coups candidats que son expérience lui dicte. C'est à peu près ce que ce nouveau programme apprend à faire petit à petit.
|
|
|
Effectivement, l'apprentissage c'est de la force de calcul brute et cette méthodologie peut pas être appliquée sans de gros moyens derrière. Et effectivement en regardant un peu ça n'a sans doute rien de magique ou d'absolument génialissime, c'est + une avancée technologique. Ceci dit les résultats sont impressionnants et succeptibles bien + que les programmes traditionnels d'améliorer notre compréhension du jeu, d'amener de nouvelles idées stratégiques ou positionnelles.
Et, quelque part Meikueilu, alphazero ne met pas de mot dessus mais il a decouvert l'opposition. Désormais il joue comme ca sans avoir besoin de calculer, comme le ferait un humain.
|
|
|
Par ailleurs c'est pas 4 TPU mais plusieurs milliers pour la phase d'apprentissage selon l'article. 4 TPU c'est pour jouer. Je n'y connais rien mais apparament c'est beaucoup si on en croit Meikueilu. En fait il y a peut étre une semi arnaque dans cette affaire de 70000 positions/seconde contre bien + pour stockfish, ce qui laisse croire que le programme une fois entrainé n'a plus besoin de réfléchir (=simuler plein de suites de parties) et peut être lancé sur son ordi perso. En réalité ça a l'air de rester trés lourd en terme de puissance de calcul, c'est juste qu'il les cible bien et donc que sur le seul critères du nombre de positions envisagées par seconde il est économe.
|
|
|
@Meikueilu "Ce qui serait une vraie avancée à mon sens ce serait de voir un programme partant de zéro et dont on puisse dire: tiens il a découvert l'opposition et il peut montrer à quoi ça sert."
Mais ça ce sont des concepts purement humains, vouloir qu'une machine s'en serve est une approche anthropomorphique. Nous fonctionnons de cette façon, nous classons les faits pour les comprendre mais il n'y a pas de raison de penser que pour être intelligente une machine doit utiliser des concepts humains.
Où ce serait fort c'est qu'une machine puisse s'adapter au mode du fonctionnement du cerveau humain pour nous expliquer ses coups. C'est à dire que même si elle ne s'en sert pas pour jouer elle serait capable d'identifier des concepts adaptés à notre façon de réfléchir pour nous les expliquer, elle pourrait par exemple écrire un livre illustrant un concept qu'elle
a découvert pour nous, avec exemples, exercices, etc.
Imaginons que nous n'ayons pas découvert le concept d'opposition, la machine n'en a pas besoin pour jouer, ça ne lui est d'aucune utilité, mais est capable d'identifier le principe dans le seul but de nous l'expliquer. Pour l'instant c'est l'inverse qui a été fait (à l'exception d'AlphaZero), on a expliqué nos concepts aux machines.
Ce qui serait amusant c'est que ces concepts issus de la réflexion d'une machine et qui auraient pour but de nous faire progresser seraient sans doute différents de ceux que nous utilisons.
Bon, avant que notre smartphone s'improvise prof d'échecs entre deux sms il va falloir attendre un peu. Peut-être que si on arrive à mettre au point un ordinateur quantique...
|
|
|
Alpha zero est peut être avantagé par le rythme rapide. Sachant qu il perd beaucoup moins de temps en calcul inutile . En gros
1 min/ coup c est peut être un temps optimal pour alpha zero mais pas pour stickfish?
|
|
|
Bien sûr j'approuve ce que dit Meikueilu : en effet les 9 heures d'apprentissage sont un peu une arnaque marketing. Cependant, même si la phase d'apprentissage est très coûteuse en temps de calcul il faut aussi penser qu'une fois effectuée, le programme joue beaucoup mieux que le meilleur module actuel sur un hardware comparable j'imagine.
Autrement dit, on a pu se passer de toute la laborieuse connaissance mise par les programmateurs dans les modules d'échecs depuis tout de même 50 ans pour s'apercevoir qu'il était plus efficace qu'un réseau assez performant l'organise lui-même. Rien que ça (même si à titre personnel ça ne me surprend absolument pas) est révolutionnaire et pose beaucoup de questions sur d'autres domaines : est-ce qu'un jour un réseau de neurones pourra prédire l'avenir de l'univers et nous pourrons juste lire les résultats sans rien y comprendre ? (un peu déprimant à mon avis).
|
|
|
Je ne minimise pas du tout la prouesse technologique et ce qu'elle peut impliquer, mais en l'occurence non, même pendant les parties, le hardware n'était pas du tout comparable (les articles de chess.com et chess24 et les commentaires en parlent). Apres apparament stockfish plafonnerait un peu.
|
|
|
sur un matériel comparable, à voir...
Adrct remarque à juste titre que le critère des posit par seconde n'est pas forcément pertinent.
Faire tourner Alpha sur un simple PC n'est pas pour tout de suite je pense.
|
|
|
A combien est estimé alphazero 4000 Elo ?
|
|
|
64% à Stockfish donc que 3300 cette buse
|
|
|
donc si je vous lis bien, les 9h c'est du pipeau vu la puissance de calcul on serait plutôt à plusieurs années ... et de toute façon l'opposition n'était pas optimale car Stockfish tournait sur un Pentium 2 / 400 MhZ (j'exagère volontairement)
Donc finalement ce n'est pas aussi spectaculaire / révolutionnaire que ça. J'ai bien suivi ?
|
|
|
c est plutôt au niveau du concept que c est révolutionnaire : c est de de l auto apprentissage, par la pratique du jeu contre soi même. c est donc plutôt le modèle humain d'apprentissage , mais en accéléré grâce à la puissance informatique.
le go et les échecs ne sont qu'un prétexte, pour le sujet principal qui est : peut on utiliser la même technique pour maîtriser à la perfection n importe quel problème intellectuel??
grossièrement l'idée serait de se dire :
est il possible que tous les problèmes intellectuels résolus par l’humain depuis 10 000 ans puissent être "re-résolus" et même au delà, par une machine que l on ferait tourner quelques heures sur le mode "trial and error" ???
une des difficultés me semble être que le sujet "échecs" se prête bien à cette technique , car il y a à chaque fois le résultat d'une partie ce qui permets de mesurer la performance, dans des problèmes plus abstraits je ne vois pas trop ce que serait l équivalent du gain de la partie pour mesurer que telle action est bonne ou mauvaise??
|
|
|
Ne crachez pas dans la soupe, bien sûr que c'est spectaculaire et révolutionnaire.
Entre un algorithme de calcul qui tourne à fond pour parcourir les variantes et les évaluer sur des critères qu'on lui a donné et un système qui apprend tout seul à jouer il y a un monde.
Il reste à savoir si ça va être une expérience unique qui restera limitée ou si dans quelques mois on remplacera tous Stockfish par un moteur d'analyse basé sur cette conception.
Quand on regarde des parties commentées en direct il est courant que le GM à l'analyse explique que dans la position l'ordi ne comprends pas grand chose et qu'il ne faut pas tenir compte de son évaluation. La tendance risque maintenant de s'inverser avec des ordis qui comprendront mieux la position sur le plan de la stratégie, des idées, et de GM qui seront à la ramasse et pas uniquement pour des considérations tactiques. Quand on voit les parties d'AlphaZero on se demande si l'être humain a réellement compris quelque chose aux échecs.
|
|
|
en fait , je ne lis pas exactement la même chose
sur 100 parties,
alfazero avec le blancs a gagné 25 parties et fait nulle 25 fois ( aucune défaite)
Stockfish avec les blancs a gagné 3 parties et fait nulle 47 fois ( aucune défaite !!)
il y a bien sûr une écrasante déculotté pour Stockfish mais il faut noter que le "joueur" ayant les blancs ne perd jamais ici!
et que la nulle semble être la règle pour des joueurs aux alentours de 3300 élo.
ce qui, sans être une résolution du jeu, me semble parfaitement en accord avec un jeu à somme nulle où le trait est un gage d'invincibilité ( sinon de gain forcé )
en corolaire: il n'y a pas lieu de s'étonner des nombreuses nulles au grand prix de Londres puisqu'en toute logique, avec des joueurs de ce niveau ce devrait être la règle s'ils jouent au mieux! Ce grand prix de Londres semble donc être d'un très haut niveau !
en fait cette étude réhabilite ces nulles comme étant des parties de haut niveau, et les gains comme le témoignage d'une faiblesse ( ponctuelle/gaffe) adverse.
le bilan AlfaZero vs Stockfish est donc plus précisément ( sur 100 "rencontres")
25 gains 72 nulles 3 défaites
|
|
|
Sauf que Stockfish a perdu trois parties avec les blancs, et non pas gagné ;-)
|
|
|
Avant d'essayer de minimiser la prouesse de DeepMind, regardez les parties.
Stockfish joue "comme un ordi à 32", AlphaZero joue "comme un humain à 33."
Ca n'a strictement rien à voir avec un module à la stockfish / houdini / deepblue qui serait hyper puissant grâce à la force de calcul de google. Ni dans la conception, ni dans le jeu.
Et puis bon Stockfisch avec 1min par coup et 64 GB de ram, c'est pas si mauvais :)
|
|
|
exact Polmipoque,
" AlphaZero convincingly defeated all opponents, losing zero games to Stockfish"
donc 28 gains 72 nulles 0 défaites pour AlphaZero vs Stockfish
mea culpa :
Petiteglise, je ne cherche surement pas à minimiser la prouesse de DeepMind! un programme qui "apprends seul" en quelques heures et reste sans égal au terme de cet apprentissage éclair... je ne vois pas comment (ni pourquoi) on peut minimiser!
ma réflexion était sur le jeu d'échecs, et non sur l'IA qui est un tout autre domaine, en devenir
|
|
|
Plus de 25% de parties gagnantes, ça montre bien que même à ce niveau il reste des possibilités importantes de gain.
Une question tout de même, stockfish n'est-il pas pénalisé par son répertoire d'ouverture ? C'est dans cette phase qu'on lui a appris le plus de choses, des ouvertures qui jusque là nous semblaient bonnes mais qui finalement le font souffrir contre AlphaZero.
|
|
|
Mea culpa, ce n'est pas 9 fois plus mais bien 900 fois plus de coups par secondes que calculait stockfish.
@Torlof : je ne disais pas ça pour toi ;)
|
|
|
JLuc74, je pense qu'en jeu idéal le résultat est la nulle! et qu'une possibilité de gain n'existe pas contre un adversaire jouant "idéalement"
Stockfish n'était simplement pas à la hauteur d'AlphaZero.
|
|
|
« que 3300 cette buse » est évidemment ironique
« est il possible que tous les problèmes intellectuels résolus par l’humain depuis 10 000 ans puissent être "re-résolus" et même au delà »
Clairement oui. Les singes sont en préretraite.
|
|
|
Il ne s'agit pas de minimiser la performance d'AlphaZero, mais juste de ne pas non plus occulter certaines réalités indiscutables :
-certes, AlphaZero a appris en 4h, mais avec 5000 superordinateurs connectés. Ca correspond à + d'1 vie humaine avec un ordi qu'on trouve dans le commerce.
-même après avoir "appris", AlphaZero ne tourne pas sur un hardware classique.
-il y avait une très grosse différence de hardware entre Stockfish et AlphaZero pendant leurs parties.
-Certes Alphazero considère juste beaucoup moins de positions, mais par contre il les analyse bien plus profondément et surtout avec des méthodes d'évaluation couteuses en temps de calcul.
AlphaZero, même en partie et même après avoir longuement appris, est plus couteux en calcul que Stockfish (ou alors j'y comprends rien !).
C'est donc avant tout une prouesse technologique bien bourrine, même si effectivement AlphaZero se rapproche d'un type d'intelligence "humaine" (reconnaissance de pattern et donc élimination ""intuitive"" des analyses inutiles).
L'intérêt est avant tout dans le résultat :
-Ca peut permettre de faire avancer la compréhension humaine du jeu, de se rapprocher de la vérité, d'accéder à des vérités stratégiques que l'homme aurait peut être mis beaucoup de temps à découvrir.
-Un système qui apprend sans aucun apriori humain devient au bout d'un moment plus performant qu'un système qui apprend avec les apriori des meilleurs humains. La version AlphaZero est meilleure que la version Alpha+aprioriDeCarlsen.
|
|
|
Je serais curieux de connaître des résultats concernant le shogi, notamment dans les parties contre lui même. Au shogi il y a quasiment pas de parties nulles, et commencer la partie est un avantage minime par rapport aux échecs (au niveau humain au moins).
|
|
|
@Torlof : on est bien d'accord, il est peu probable que dans la position de départ on puisse dire "les Blancs jouent et gagnent", les Noirs ont trop de possibilités de défense.
Ce que je veux dire c'est que contre un adversaire à 3200 Elo (Stockfish) un meilleur programme gagne encore 25% de ses parties, donc qu'à 3200 Elo on joue des coups perdants dans au moins 25% des parties. Et si on considère que plus le niveau est élevé et plus il y a de nulles alors au niveau des meilleurs mondiaux (2800 Elo) il pourrait y avoir plus de 25% de gains, peut-être 30% ou 35% et il me semble qu'on est sensiblement en dessous.
|
|
|
Quelle révolution! Tout le monde (ou presque) en parle!
chess.com
Chess24
schaaksite.nl
Chessbase
la BBC
|
|
|
Je suis déçu, ils n'en parlent pas dans Gala
|
|
|
Ni sur EE. hum hum...
|
|
|
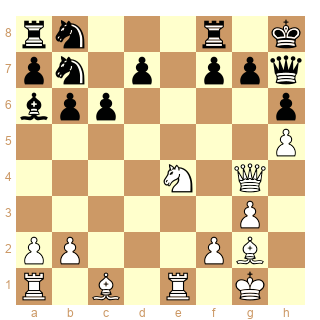
21.Fg5!! gagne.
Hallucinant!
|
|
|
@Adrct: au shogi, contre le programme Elmo,
avec Blanc (gote) : +43 =2 -5;
avec Noir (sente) : +47 =0 -3.
|
|
|
je suis un profane mais je crois quand même comprendre qu'il y a 2 versions de l'histoire : celle rapportée par la presse et par PE (entre autres), et celle rapportée par Ardct
Ce n'est pas exactement la même, puisque la puissance de la machine est bien moindre. J'entends bien que SF calcule 900 coups de plus à la seconde, mais ça à la limite c'est sa spécialité par rapport à AZ. Et AZ a sa spécialité par rapport à SF qui est "d'apprendre tout seul" (je schématise parce que je n'y comprends pas beaucoup plus).
Mais la vraie question demeure : sur une machine semblable, qui gagnerait ? Et si SF gagne, au bout de combien de temps AZ devient assez fort pour "apprendre de ses erreurs" (un temps qui doit se mesurer en fonction de la puissance de l'ordi si je comprends bien).
J'essaie d'aller au-delà de ce qui est écrit dans la presse. Donc oui dans un sens je cherche à minimiser la prouesse, si on veut le dire comme ça, mais c'est un trait commun chez les joueurs d'échecs quel que soit le sujet ! Donc pourquoi pas aux échecs aussi ?
|
|
|
Il faudrait que quelqu'un équipé d'un matos aux performances très haut de gamme nous disent en combien de temps stockfish trouve des coups comme Fg5
|
|
|
Même Blitzstream en parle sur YouTube, finalement c'est un peu comme Gala : https://www.youtube.com/watch?v=PH06mEOVVyY
|
|
|
J'ai essayé de faire tourner Stockfish sur mon petit portable, Fg5 il ne voit, et si on le joue il ne voit toujours pas que ça gagne avec une profondeur de 30. Il propose f5 +0.0 comme réponse, je regarde la suite
|
|
|
De 1 Stockfish évalue la position comme "égale" avec les deux pions de moins ce qui doit mettre la puce à l'oreille de tout utilisateur averti et de 2 après Fg5 il indique f5 comme seul coup (évalué à 0.00 ce qui doit encore mettre la puce à l'oreille d'un utilisateur averti) jusqu'à une profondeur de 38. (La bascule se fait entre la profondeur 37 et 38 sur mon PC : elle est atteinte en un peu plus de 2 min) Après quoi il comprend qu'il est foutu.
|
|
|
Tu as atteint la profondeur 37 en 2 mins ? Tu as quoi comme bolide ?
Chez moi, il commence à apprécier Fg5 à profondeur 36 (+0,63) au bout de 25 mins
J'ai besoin d'une explication de la page 6 du lien proposé par Petiteglise.
Si je prends le cas de l'Anglaise, les résultats affichés sont Alphazéro contre Alphazéro ? Ou Alphazéro contre Stockfish (dans ce cas, ils ont joué 1200 parties)
Je ne comprends pas le 20/30/0 et le 8/40/2 (si c'est Alphazéro contre Alphazéro). les résultats sont meilleurs pour le 1er avec les blancs et les noirs ??
A quoi correspond la courbe ? C'est une échelle de temps en abscisse ?
La Berlinoise n'est pas "testée" dans les positions.
Par quel cheminement Alphazéro a-t-il choisi de l'utiliser contre Stockfish si cette ouverture n'a pas été testée avant ?
|
|
|
J'ai un Core i7 relativement performant soutenu par 48 GO de RAM et je ne bosse que sur des SSD. En tant qu'entraîneur pro je passe pas mal de temps à travailler sur des bases volumineuses et si tu perds 3 min à chaque demande à la fin de la journée il te manque une heure facile. C'est une config superflue pour un usage domestique mais je suis très loin de ce qui se vend sur le marché pro d'aujourd'hui.
|
|
|
J ai l impression que chez alphazero le critère d équilibre matériel est moins important que chez les humains et les modules . Il me semble qu il a moins peur des sacrifices avec retour non immédiat ou incalculable. Cela voudrait dire que certains avantage dynamiques sont équivalents à un avantage permanent ? Le joueur humain est en général réticent face à cette idée car il a peur qu un avantage dynamique finisse par s évaporer et que ne subsiste que le désavantage matériel.
La vérité du jeu est peut être au delà de l équilibre matériel et doit faire appel à l équivalence matière/énergie ?
|
|
|
48 Go ah oui quand même
|
|
|
En effet, c'est loin de ce que l'on peut utiliser professionnellement ;-)
Mon ordi de test au boulot est à 100Go de Ram pour 12 coeurs et c'est pas suffisant ;-)
|
|
|
Vous savez où récuperer le .pgn des parties ?
|
|
|
vous bossez tous au CERN ?
|
|
|
@ SLM : Ça coute combien un config comme la tienne ?
@PowerDuck : Tu peux te les faire avec les parties données par Petiteglise.
Sinon personne n'a répondu à mes questions ;-(
|
|
|
@mop, si on en croit la légende de leur graphique, effectivement ils ont joué + que 100 parties. Certaines avec des ouvertures imposées, et Stockfish en a gratté quelques unes notamment quand AlphaZero joue la sicilienne (ce qu'il ne fait plus quand il est pas forcé de le faire).
Pour ce qui est de la Berlinoise, il l'a joue /l'a joué contre lui même quand il joue/jouait 1)e4 (le principe pendant l'apprentissage c'est qu'il continue quand même de temps en temps à jouer des coups "sous optimaux" de son point de vue pour continuer d'explorer diverses pistes même celles qui lui semblent probablement moins intéressantes à ce stade de son apprentissage).
Ca n'apparait pas dans les graphiques car ils ont décrété que ça ne faisait pas parties des "12 ouvertures humaines les + populaires", mais si tu remarques bien le total des pourcentages de parties jouées dans ces ouvertures par AlphaGo n'atteint jamais 100% donc probablement qu'il s'entraine ou s'est bien entrainé sur la Berlinoise à un moment donné
|
|
|
Est ce que Stockfish est par nature limité, ou potentiellement si on branche Stockfish a un gigaordinateur hors du commerce il devient bien plus performant ?
|
|
|
A l'époque (en 2013) aux alentours de 2200€. Aujourd'hui je dirai que pour 1800€ tu as un équivalent sans souci.
|
|
|
@mop chaque "ouverture" a été testée durant 100 parties vs Stockfish.
Résultats gains/nulles/pertes sur les 1200 parties.
Total games: w 242/353/5, b 48/533/19 Overall percentage: w 40.3/58.8/0.8, b 8.0/88.8/3.2
Soit 61% pour AlphaZero, un peu moins que quand il a pu jouer "son répertoire" dans le "vrai match"
|
|
|
"""
Si je prends le cas de l'Anglaise, les résultats affichés sont Alphazéro contre Alphazéro ?
Ou Alphazéro contre Stockfish (dans ce cas, ils ont joué 1200 parties)
"""
Les deux en réalité. Pour les ouvertures mentionnées, ils ont forcé AlphaZero à jouer à partir de la position représentée (ici 1.c4) contre Stockfish sur 100 parties (50 avec chaque camp). Le score est celui d'AZ soit avec les blancs 20 victoires et 30 nulles et 8 victoires, 40 nulles et 2 défaites avec les noirs. Après, ils ne mentionnent ni la cadence ni quand (après ou pendant l'apprentissage).
"""
A quoi correspond la courbe ? C'est une échelle de temps en abscisse ?
"""
La courbe correspond à la popularité de l'ouverture au fil du temps (en heures) lors de la phase d'apprentissage. L'anglaise est toujours jouée tandis que la française est moins populaire à mesure que l'apprentissage se fait.
"""
La Berlinoise n'est pas "testée" dans les positions.
Par quel cheminement Alphazéro a-t-il choisi de l'utiliser contre Stockfish si cette ouverture n'a pas été testée avant ?
"""
Pas besoin de tester les ouvertures une par une. Il les explore en jouant contre lui-même et en fonction du résultat les "ajoute à ses préférences" en quelque sorte.
@elkine
Non une petite PME et c'est une assez vieille machine.
|
|
|
48 GO de ram c est pas bien SLM moi j'en ai 64 et c'est mieux de mettre un 2^x style 32 dans ton cas...
|
|
|
C'est un petit peu plus compliqué que cela mais en général il est conseillé effectivement d'avoir une config en 32 ou 64. Dans mon cas je n'ai pas besoin de 64 et 32 ne me suffisait pas mais c'est très spécifique à mon usage.
|
|
|
pourquoi 32 ou 64 ? ça dépend du nombre de cœurs non ?
|
|
|
Faudrait demander à @Meikueilu ou à un autre informaticien de métier : mes connaissances sont rouillées sur le pourquoi du comment. Le fait est que les constructeurs proposent et conseillent en général d'utiliser une puissance de 2. Il y a également le dual channel qui rentre en compte.
Néanmoins quand tu utilises un logiciel qui pompe toute la RAM dispo mais dans la limite d'une puissance de 2 ben tu te rends compte que ton PC ne tourne plus à côté. D'où les 48 chez moi : 32 pour le module, 10 pour le cache de la base de référence sous Chessbase et le reste pour que mon PC ne décède pas. ;-)
|
|
|
Merci pour vos éclaircissements.
L'Anglaise semble être la "plus populaire" et pourtant il n'y en a aucune dans l'échantillon des parties.
Je teste la position de la 3ème partie suggérée par Petiteglise avec le 47.Txc5
Je suis à profondeur 49 et Stockfish préfère Df4 (+0,40) et ne donne qu'une perpétuelle sur le sacrifice de qualité.
|
|
|
Ma préférée, avec celle que P-E a montrée plus haut, c'est la Française avec 30.Fxg6!!! Si un humain joue ça, c'est qu'il est 1300 et a raté 30...Fxg5 intermédiaire: il donne juste une pièce pour un pion... sauf que les Noirs sont totalement ligotés, et ce même en parvenant à échanger les Dames. On en arrive à la position du diagramme, où l'élégant 40.Tg1!! parachève le zugzwang.... Thank you, good game.
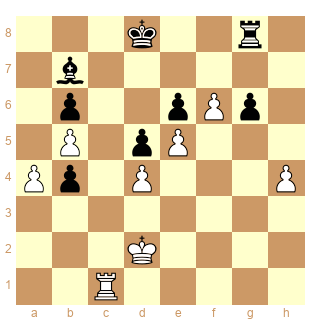
|
|
|
Ca a l'air assez extraordinaire certains coups en effet...
Quelqu'un s'intéresse aux compétitions entre ordinateurs ?
AlphaZero a vraiment l'air de jouer d'une autre manière, de faire rentrer le jeu dans une autre dimension ?
|
|
|
la dernière est pas mal non plus avec Dh1-h3 et 32.c4 ! (il faut le voir...)

|
|
|
Il y a une explication au Tf8 de Stockfish plûtot que Rf8 dans la première partie montrée par Petiteglise (avec Txc5!!).
Le stockfish de lichess donne instantanément Rf8 0.00 et voit directement que Tf8 perd.
Il y a un gain caché après Rf8 ?!
|
|
|
Edit bon Ok ca change plus ou moins rien
|
|
|
Merci à Petite Eglise pour ces informations passionnantes...et effrayantes tout à la fois !
Je ne pensais pas que "quelque chose" pouvait battre Stockfish 28 à 0 de mon vivant et cela arrive en 2017 !
Les informaticiens qui ont imaginé cette "chose" alphachess sont vraiment stupéfiants ...
naturellement quand on connait la force de Stockfish aux échecs...il semble inimaginable qu'un joueur humain puisse battre alphachess en partie de tournoi à la pendule... (peut-être en jeu par correspondance?).
Je ne sais pas si "l'intelligence artificielle " est une illusion , un cauchemar, ou un événement inéluctable dans un proche avenir, mais je me demande dans quelle mesure Google qui est une entreprise privée , ne va pas cristalliser sur elle toutes les frayeurs et peurs de près de 7 milliards d'humains ...et au final avoir très vite une image détestable dans le grand public...qui a fait d'elle ce qu'elle est aujourd'hui : puissante, inquiétante, incontournable ... elle n'y survivrait pas si elle devient le symbole de toutes nos peurs inconscientes sur "l'intelligence artificielle " (Matrix, terminator etc... ont profondément modelés nos fantasmes depuis Shelley et Frankenstein).
Les exemples de parties donnés sur la qualité de jeu de alphachess vs Stockfisch sont vraiment stupéfiants pour l'amateur que je suis.
Cordialement à tous sur le forum
|
|
|
Moi aussi, ma préférée, c'est la Française de Raspoutilf. En même temps, c'est la première que j'ai regardée. Mais quel pied ! La Traviata, avec Anna Netrebko, m'avait fait le même effet.
Rien à voir avec les parties habituelles entre modules où grosso modo celui qui voit le plus loin et le mieux prend l'avantage petit à petit et convertit après un récital technique qui n'a pas grand-chose d'humain.
J'espère que l'on aura bientôt (Twic?) toutes les parties.
|
|
|
En fait à l'époque on avait notre Kasparov comme représentant du meilleur jeu connu à l'instant "T" et Deep Blue a symboliquement montré la supériorité de la machine. "Nôtre" Stockfish a trouvé son "Deep Blue"!
|
|
|
"il semble inimaginable qu'un joueur humain puisse battre alphachess en partie de tournoi à la pendule"
Si Carlsen veut se faire ridiculiser...
"Mais quel pied !"
"Rien à voir avec les parties habituelles entre modules"
+1
Enfin un module qui fait du beau jeu.
|
|
|
heureusement il reste prenable en blitz
|
|
|
il fait ses roques à 2 mains, j'en suis sûr !
|
|
|
J'ai laissé tourner la position avec Txc5.
Stockfish ne voit toujours pas mieux à profondeur 54.
|
|
|
@Orouet : devrait lui prendre une heure ou deux d'apprendre à contrôler des bras...
|
|
|
Plusieurs réponses aux questions posées ici dans la vidéo de BlitzStream :
https://www.youtube.com/watch?v=PH06mEOVVyY
|
|
|
Oui, très bonne vidéo. Avec le retour de Mathieu Acher, dont je n'avais plus entendu parler depuis ses années
en championnats de France jeunes, et qui fait une sacrée belle carrière hors échecs.
C'est le Joueur d'échecs de Stefan Zweig qui avait fait pareil (niveau champion du monde en n'ayant joué que face à lui-même).
|
|
|
coupez lui l'alimentation électrique.
|
|
|
C'est vrai que c'est étrange qu'EE ne traite absolument pas du sujet.
Je dirais que c'est là nouvelle la plus importante concernant le jeu depuis, mettons la perte de son titre, en 2002, par Garry.
Sinon, vu le nombre de gains que Alpha Zéro arrive à planter à Stockfish, finalement le problème des nulles entre humains, c'est la très grande homogénéité du top.
Carlsen a été stratosphérique pendant des années, Caruana, So, Aronian... pendant quelques mois, dans ces cas là, il y a un écart de niveaux, des gains, des victoires en tournoi, des records élo.
Mais s'ils sont "normaux" il n'y aurait plus assez d'écart de force pour qu'ils se départagent !?
|
|
|
La seule chose qui peut compenser pour le jeu humain, peut-être, c'est que l'humain peut choisir une ligne "molle mais avec tendance annulante" contre un joueur un peu plus fort que lui au top niveau, ce que Carlsen essaie d'éviter. Si Stockfish était programmé pour viser la nulle et non pas toujours le "plus prometteur" peut-ětre qu'il aurait eu le niveau suffisant pour faire 100% de nulle contre AlphaZero? Mais peut-être que programmer un mode de jeu "annulator" n'est pas si simple car l'ordinateur pourraît se tromper en ne voyant pas être perdant. Est-ce plus facile de compliquer ou de somplifier le jeu dans le cas ou un Capablanca Stockfish affronte un Alekhine AlphaZero?
|
|
|
Pour répondre à ma propre réponse je peux déjà dire que choisir cette façon de jouer est plus facile avec les Blancs, et que j'imagine que seul un répertoire adapté permet de le faire d'entrée de jeu au niveau 3400 avec les Noirs (genre Berlin vs e4, GDR contre d4 par exemple).
|
|
|
"Mais peut-être que programmer un mode de jeu "annulator" n'est pas si simple"
Peut être qu'avec l'aide de Giri... lol
|
|
|
@Arkhein : tu as tout à fait raison. Les modules actuels en général, et ceux du top en particulier (houdini, stockfish et komodo) ne sont absolument pas programmés pour s'adapter au niveau de l'adversaire (viser la nulle si l'adversaire est plus fort par exemple). Je ne sais pas si c'est facile, mais un premier pas peut sûrement être fait en réglant le "contempt" (cad la valuation de la partie nulle) de façon plus gratifiante lorsqu'on joue contre un adversaire plus fort.
On remarque aussi que Stockfish a fait jeu égal avec les blancs, sans répertoire d'ouverture. Alors que AlphaZero avait son propre répertoire construit par apprentissage (même s'il ne s'agit pas d'un répertoire à proprement parler).
Bref, il ne faudra peut-être pas très longtemps pour qu'on n'ait plus que des nulles entre top modules.
Pour finir, j'ai exprimé des réserves en disant que le temps de calcul est énorme pour l'apprentissage de Alpha Zero (bien loin des 9 heures marketing servies par Deep Mind, un temps de calcul ne se compte pas en heures !). Mais j'aimerais dire aussi que la façon dont joue le programme est absolument magnifique. On a réussi à créer une façon beaucoup plus humaine de jouer que celles des modules du top, et beaucoup plus efficace aussi.
|
|
|
Stockfish n'avait pas de répertoire d'ouverture ou pas de répertoire optimisé ?
Qu'importe, en regardant les parties je n'ai pas l'impression que ça se soit joué à ce niveau.
|
|
|
La Française ne semble pas avoir été jouée au mieux. Pour la Ouest-Indienne c'était une vrai raclée, entre autre dans ce gambit Polougaevski. Certes l'Ouest Indienne n'est pas réfutée mais ça offre des chances de +/= et j'ai l'impression que Stockfish n'a pas joué une des lignes les plus solides de la variante Polou.
|
|
|
bah jouer la française n'était probablement pas un bon choix pour Stockfish, n'est-ce pas ? Si j'ai bien compris, Stockfish n'avait pas de répertoire d'ouvertures. Avec un répertoire solide, le score de alpha zero tomberait sûrement en dessous de 60%.
Mais de toutes façons, peu importe, maintenant il faut que les programmeurs de module suivent la voie alpha zero, qui semble de loin la plus prometteuse.
|
|
|
''On remarque aussi que Stockfish a fait jeu égal avec les blancs''. Oui, c'est ce qui m'étonne. Cette énorme différence de score entre les blancs et les noirs. Comment, avec ses faibles moyens, Stockfish parvient il à neutraliser le monstre ?
|
|
|
Il est probable que le caractère annulant intrinseque au jeu d'echecs limite effectivement l'écart de score entre un programme traditionnel optimisé et Alphazero. Le jeu en lui même n'est pas assez discriminant. Pour caricaturer au morpion même moi je fais aussi bien qu'alphazéro. Par contre au go et au shogi je pense qu'un AlphaZero encore un peu entrainé devient imbattable par des programmes classiques et scorera 100%
|
|
|
Au sujet des ouvertures, je trouve les résultats de l'article intéressants, mais ils soulèvent plusieurs interrogations.
- sur le chronologie : on dit que Alpha a d'abord essayé la française, puis la caro-kann pour finir par préférer l'espagnole, puis l'anglaise et le gambit-dame. Le problème que je vois ici : on mélange les blancs et les noirs. Une interprétation (correcte ?) me semble être que en effet, la française et la caro-kann n'ont pas réellement tenu le choc avec les noirs. Puis la ruy lopez a fait le job. Du coup Alpha Zero s'est orienté avec les blancs vers les ouvertures fermées (1.d4 et 1.c4).
- sur les résultats contre Stockfish. Je prends l'exemple particulier de l'est indienne (en fait c'est la Grunfeld !). Alpha Zero s'est moins entraîné sur cette ouverture durant son processus d'apprentissage (car il l'a trouvé moins intéressante pour répondre à 1.d4). Du coup, il est probable qu'il la joue moins bien que d'autres ouvertures. Cela explique peut-être qu'il n'a pas réussi à en gagner une avec les noirs.
|
|
|
Hum on ne peut plus se fier a Stockfish qui annonce 0.00 dans beaucoup de positions, même avec un ordinateur rapide.
|
|
|
@chemtov : en effet avec les noirs, alpha zero a atteint 6% de gains et 94% de nulles. Mais on n' pas toutes les parties, par exemple on ne sait pas si Stockfish a toujours joué 1.e4 ou aussi d'autres premiers coups dans ce match en 100 parties.
Des éléments de réponse : sur 1.e4 alphazero est arrivé à la conclusion que la meilleure ouverture noire était la berlinoise; pas étonnant qu'il n'en ait pas gagné beaucoup (ni les blancs).
Par ailleurs, d'autres parties ont été jouées avec ouvertures forcées, et dans ce cas, alphazero a atteint 8% de gains avec les noirs, ce qui n'est pas beaucoup plus.
Explication possible : en s'entraînant contre lui-même (et pas contre un adversaire plus faible), AlphaZero a probablement favorisé les réponses les plus solides avec les noirs dans l'ouverture (peu de Grunfeld et d'Est Indienne par exemple) et pas les plus aventureuses. Du coup il se trouve un peu démuni pour jouer pour le gain.
Autre explication : on a aussi l'impression qu'ils ne sont pas loin d'avoir "résolu" le jeu et ceci n'a pas trop été souligné dans tous les commentaires : lorsque le plus fort des deux a les noirs, ça fait forcément nulle (son adversaire n'est quand même pas une quiche et est assez fort pour annuler avec les blancs, même contre un monstre).
|
|
|
Comme quoi Kramnik a eu du nez en exhumant la Berlinoise. Quel talent !
|
|
|
oui et MVL doit se mettre à 1.d4/c4/Cf3 de toute urgence.
Sinon j'ai regardé un peu plus les parties publiées et en effet, Stockfish a joué les Ouest Indienne de façon assez atroce.
|
|
|
"Alpha Zero s'est moins entraîné sur cette ouverture durant son processus d'apprentissage"
A moins avis il a surtout appris à évaluer les positions sur ses propres critères plus qu'il ne s'est construit un répertoire. Si ça a joué c'est parce que les types de position dépendent des ouvertures jouées. Mais quand il joue contre lui-même il doit ensuite chercher d'autres solutions, donc sans doute des ouvertures bien différentes, pour éviter de perdre ou même de faire nulle.
Je serais curieux de savoir combien de parties il gagne contre lui-même. Qu'est-ce qui se passe si des versions de lui même s'entraînent contre des moteurs ou de très forts joueurs différents et qu'ensuite ces deux versions jouent entre-elles.
"on a aussi l'impression qu'ils ne sont pas loin d'avoir "résolu" le jeu"
J'ai l'impression contraire, le jeu d'AlphaZero est très innovant, il ouvre de nouvelles voies.
Ce qui est intéressant c'est qu'il comprend le jeu sur la base de critères bien plus objectifs que ne peut le faire un être humain. Chaque joueur humain, et c'est vrai aussi pour les moteurs classiques, évalue la position de façon subjective, en fonction de ses connaissances. Par exemples certains préfèrent les Cavaliers aux Fous. AlphaZero au contraire doit nous permettre de mieux comprendre ces critères d'évaluation. Dans un sens il cherche pour nous.
|
|
|
c'est marrant ce débat dans le débat (est ce que AlphaZero a quasiment résolu le jeu ou est ce qu'au contraire a permis de se rendre contre qu'on en est loin). J'ai l'impression que pas mal de gens dont de très fort joueurs disent que le jeu est quasi résolu, alors que comme JLuc, la réaction spontanée de MVL sur Twitter a été de dire 'quand tu as réalises que le jeu d'échecs n'est pas du tout résolu'..
|
|
|
Bah... ça fait parler des Echecs, c'est l'essentiel.
|
|
|
@JL : l'apprentissage par renforcement consiste à traiter de mieux en mieux une certaine tâche à force de la traiter (donc à force d'entraînement).
Le renforcement est basé sur le résultat de la partie, ce qui signifie qu'au fur et à mesure de l'apprentissage, alphazero favorisera les coups qui donnent les meilleurs résultats en moyenne (pour simplifier). Par ailleurs, dans un état donné du réseau (à une certain moment de l'apprentissage), et pour une position donnée du jeu d'échec à traiter, alpha zero ne choisira pas toujours la même réponse : tous les coups possibles sont en effet listés et assortis d'une probabilité d'être joués. Par exemple, les coups évalués comme très mauvais ont une probabilité ultra faible (voire nulle) d'être joués. Les coups un peu douteux seront joués assez peu souvent.
Une fois qu'on a compris ça et qu'on regarde les graphiques publiés, on a facilement la conclusion suivante : alphazero joue moins la grunfeld que la slave car cela lui donne de moins bons résultats en moyenne. Mais cela ne signifie pas que la Grunfeld est réfutée. Par conséquent, en jouant moins souvent la Grunfeld, il l'apprend moins bien (car l'apprentissage se fait par répétition des mêmes tâches). Cela implique aussi qu'il la joue probablement moins bien.
JE ne sais pas combien de parties a disputé alpha zero pour s'entraîner, l'article mentionne 700 000 steps composés de 4096 batches. S'il s'agit de 700 000 x 4000 parties, cela fait de quoi acquérir des "connaissances" énormes dans l'ouverture (3 milliards de parties)
|
|
|
Ils parlaient de 44 millions de parties il me semble.
|
|
|
"Comme quoi Kramnik a eu du nez en exhumant la Berlinoise. Quel talent !"
Pas du tout ! Il etait juste au courant avant tout le monde des developpements informatiques de la bete a puces !
Cela explique aussi son choix comme WildCard pour le match des candidats ...
Je vous laisse conclure : aucun suspens en 2018, avec un tel preparateur, Vlad va pulveriser les doigts dans le nex les gamins au printemps avant de glisser quelques billes facon match contre Garry au morveux norvegien a l'automne ;)
|
|
|
@dan31 "alphazero favorisera les coups qui donnent les meilleurs résultats en moyenne"
Oui mais il y a deux adversaires, et en l'occurrence 2 fois le même. Un bon résultat pour Blancs sera un mauvais pour Noirs qui va essayer autre chose la prochaine fois, une autre variante, une autre ouverture. Il n'y a donc peut être pas de raison pour qu'il reste bloqué sur une ouverture. Surtout si il voit la nulle comme une demi-défaite plus que comme une demi-victoire.
Tant qu'on gagne avec une ouverture on la joue, mais si on perd on joue autre chose.
|
|
|
Au vue des parties, ça me laisse penser que le jeu d'alphazero aurait tendance à montrer que la vision du jeu des forts joueurs humains est plus proche de la "vérité" que le jeu des programmes actuels (avant alphazero) malgré la domination de ces derniers. Il a vraiment un sens incroyable de l'activité, que seuls les très forts joueurs et les grands champions ont... mais évidement il a les capacités de calcul des neurones en silicium en plus.
Mais oui on est certainement très très loin de la résolution du jeu je pense (même si depuis quelques années je me suis laissé convaincre que ce n'est pas un objectif inatteignable, les arguments contre du style "il y a plus de parties possibles que de particules dans l'univers" ayant en fait une valeur assez limitée)
Torlof, tu as mal lu les résultats : il suffit de regarder les parties listées dans le post initial pour voir qu'il y a des gains avec les noirs d'alphazero.
Sinon je me demande s'ils comptent appliquer leur programme à la recherche de théorèmes mathématiques. Ce serait super intéressant! En particulier la recherche de résultats prouvables sur les nombres premiers (y a tellement de lemmes non prouvés..).
|
|
|
@JL : je dis juste qu'il ne rentrera pas facilement dans la Grunfeld avec les noirs car cela lui apportera des résultats en moyenne moins bon. Et que par conséquent, il la jouera moins bien.
|
|
|
@ sigloxx : je pense qu'il y a un biais dans ta conclusion : dans ces parties, on voit la différence entre Stockfish et AlphaZero, à savoir le jeu positionnel profond, avec par exemple les sacrifices à long terme. Mais si on jouait (nous ou Magnus) contre lui, il n'y aurait pas de différence avec un autre module, ça serait une boucherie tactique typique des ordis, assez moche.
|
|
|
Peut être, néanmoins quand je me fais défoncer par un programme comme stockfish, évidement c'est toujours une boucherie tactique (et positionnelle aussi :P) mais je ne sens pas ou très rarement un sens de l'activité et un dédain par rapport à l'avantage purement matériel au point où on le sent dans les parties d'alphazero. Après c'est peut être juste lié au fait que ce soit des parties de très haut niveau, mais ça semble vraiment être sur ce facteur de l'activité versus l'aspect matériel que stockfish semble avoir des lacunes dans ses jugements des lignes par rapport à alphazero.
je pense que si un joueur comme Magnus perd contre stockfish, c'est parce qu'il va très souvent louper des trucs purement tactiques longs et difficiles à voir (et ce serait effectivement pareil s'il jouait contre alphazero, on a juste pas leurs capacités de calcul), mais je pense que MVL est plus à même que stockfish de concevoir le genre de sacrifices positionnels qu'alphazero montre dans ses parties.
|
|
|
Le paradoxe est que le module est autorisé à utiliser sa bibliothèque d'ouverture et les tablesbases de finale contre un humain mais pas contre alphazéro.
|
|
|
Pourquoi 10 parties disponibles pas les 100 parties ?
|
|
|
J'ai l'impression que "avantage matériel" est un concept moins clair désormais.
Après tout, la valeur des pièces résulte de l'expérience des forts joueurs depuis des centaines d'années, c'est donc un résultat d'apprentissage.
Je suppose que AlphaZero utilise ces valeurs au départ, mais j'aimerais savoir si petit à petit il les retouche en fonction des résultats.
Il serait alors très intéressant de voir comment elles évoluent.
Certaines parties déjà montrées sont ébouriffantes de ce point de vue !
|
|
|
sigloxx, j'avoue que je ne comprends pas ton dernier paragraphe, où il est question des deux programmes, ainsi que de Magnus et MVL. Veux-tu dire que MVL résisterait mieux à un ordi que Magnus ?? Probablement pas, mais alors où veux-tu en venir ?
|
|
|
@ANaigeon : justement non Alphazero connaît juste les règles du jeu au début de son apprentissage. Récupérer la valeur des pièces est donc probablement illusoire. On pourra juste avoir des approximations données en tant qu'espérance de gain, par exemple tu enlèves un pion aux blancs dans la position de départ et tu regardes comment varie l'espérance de gain des blancs par rapport à la position normale.
|
|
|
@ANaigeon, pour être plus clair par rapport à ce que dit dan31 : non, AlphaZero ne connait absolument pas les valeurs que nous attribuons arbitrairement aux pièces (pas sûr d'ailleurs qu'il leur donne une valeur).
Les valeurs que nous donnons aux pièces ce sont comme beaucoup de notions des principes que nous utilisons pour simplifier notre compréhension du jeu. Ces principes ce sont les joueurs qui les ont découverts et se les sont enseignés mais sont ils justes ? Pas toujours en tout cas.
En fait AlphaZero n'a aucun a priori, c'est comme un humain qui aurait juste les règles du jeu mais n'aurait jamais ouvert un livre sur les échecs ni discuté avec un autre joueur qui lui aurait donné des conseils. Il découvre tout, à sa manière, par l'expérience et le résultat est meilleur que ce que nous avons obtenu avec nos années d'expériences collectives. Il a peut-être joué le mat de l'idiot au début de sa phase d'apprentissage et quelques heures plus tard c'est lui le boss.
|
|
|
@Bibifoc : Oui, ce serait bien de voir les autres parties. Notamment les perdues. Et aussi les nulles. Comment et pourquoi ( ''pourquoi'' sera probablement plus difficile à comprendre ! ) ce monstre se retrouve en difficulté.
Quant aux sacrifices positionnels, il faut relativiser. Un sacrifice positionnel dont on voit l'issue ( récupération du matériel ou enfermement total d'une pièce adverse), dont on peut calculer les conséquences, n'est pas vraiment un sacrifice positionnel.
On en saura plus lorsqu'on aura la base avec les cent parties. Ce serait bien aussi de connaitre l'ordre chronologique des parties. Quand une ouverture se répète ( sur 100 parties ça peut arriver ...) Est-ce qu'une des deux machines va modifier ses coups ?
|
|
|
"Notamment les perdues."
Difficile, il n'a perdu aucune partie.
"récupération du matériel"
Là encore on peut se demander si il compte le matériel comme nous le comptons et comme nous avons appris aux autres moteurs à le compter. Sait-il seulement ce que c'est que gagner une qualité ?
|
|
|
A.Naigeon, désolé typo (chauvinisme inconscient?), je voulais écrire Magnus pas MVL :).
|
|
|
On entend aussi que l'équipe de Google sait bien se vendre : le résultat serait moins net s'ils avaient autorisé SF à consulter ses tables ou gérer son temps (p.ex. en 30 mn KO).
|
|
|
Alphazero m'a appelé hier soir, pour me dire qu'il avait réécrit la fin des "Misérables" ; il la trouvait un peu niaise.
Je lui ai répondu que ce n'était pas très utile, ni très respectueux envers Victor Hugo.
Il m'a sèchement rappelé que je n'étais pas son père, et il m'a raccroché au nez.
Mais bon, ce matin, il m'a rappelé pour présenter ses excuses, et il m'a dit qu'il comprenait pourquoi, au fond, j'étais malheureux depuis toujours.
|
|
|
@elkine
Pour la cadence, ils ont choisi la cadence des matches entre machines.
|
|
|
Je n'ai jamais vu de match entre machines à 1 minute par coup...
|
|
|
@atms
+1
|
|
|
25 victoires avec les blancs et seulement 3 avec les noirs ?
curieux un tel écart selon les couleurs entre deux machines aussi fortes.
Le pourcentage selon les couleurs n'est absolument pas le même entre deux joueurs humains si on regarde les megabases de données. sans vérifier je crois me souvenir que c'est environ 55/45 %.
Est ce que vous pensez que le résultat entre alphachess et stockfisch signifie que la résolution hypothétique un jour du jeu d'échecs démontrera que le gain n'est pas possible avec les noirs si les blancs commencent la partie ?
|
|
|
"Est ce que vous pensez que le résultat entre alphachess et stockfisch signifie que la résolution hypothétique un jour du jeu d'échecs démontrera que le gain n'est pas possible avec les noirs si les blancs commencent la partie ?"
Pas besoin de regarder le résultat entre AlphaZero et Stockfish, il est très probable que la résolution du jeu d'échecs démontrera que le gain n'est pas possible avec les Blancs non plus.
Dans ce domaine il n'y a pas de situations floues, si c'est "possible" avec les Noirs alors ça veut dire que la position de départ donne le gain aux Noirs. Les Blancs jouent et le gain est forcé pour les Noirs... Peu probable non ?
Et puis... si les Noirs commencent la partie est-ce que c'est encore une partie d'échecs ?
|
|
|
@atms ... +10!
la meilleure perception du phénomène "Alphazero"
...
l'appel de demain sera terrible!
|
|
|
J'ai l'impression que ''là nouvelle la plus importante concernant le jeu depuis, mettons la perte de son titre, en 2002, par Garry.'' va être le flop le plus important.
|
|
|
En terme d'IA je suis peut être un sceptique, mais je pense qu'on peut dormir tranquille..pour l'instant.
Le jeu d'échecs, c'est des règles bien définies, sur un petit plateau avec un nombre limité de pièces différentes, et surtout un objectif et une évaluation claire : gain, nulle, ou perte (les algos de machine learning ont toujours plus ou moins pour but de minimiser une fonction de perte).
Ce que fait ce programme est magnifique, et évidemment c'est une prouesse incroyable qu'il apprenne à jouer tout seul et qu'il devienne incroyablement bon en quelques heures, mais pour l'instant l'IA est encore bof bof même pour des taches qui paraissent pas hypra compliquées (même la traduction c'est pas encore complètement résolu je crois !).
Je pense qu'on est encore loin de résultats impressionnants pour des problèmes où :
-le nombre de variable à prendre en compte est très important et les règles ne sont pas fixes mais ont une dynamique aléatoire.
-le "résultat" est difficile à quantifier.
Comme le dit la vidéo de BlitzStream, il y a aussi le fait que pour pas mal de problèmes il ne sera pas aussi facile pour la machine de récolter des données pour apprendre.
Après c'est vrai qu'il va sans doute commencer à exister des livres ou morceaux de musiques créés par l'IA..Mais bon..Ce sera pas vraiment de la "création".
|
|
|
@Adrct La traduction dans une langue cible correcte, éventuellement allusive, ou humoristique, etc, est une tâche *extraordinairement complexe* !
Les traductions actuelles ne produisent qu'un charabia presque toujours ridicule, et parfois même dépourvu de sens.
|
|
|
Ca progresse la traduction. Evidemment ne pas croire que ce qu'on trouve gratuitement sur internet constitue les meilleures versions actuelles dans le domaine. Cependant les traducteurs ont encore de beaux jours devant eux, tout comme les entraîneurs d'échecs :-)
|
|
|
merci pour ce post, c'est vertigineux !
@atms : msg 20h01.je suis plié :)
|
|
|
Un robot a 'étudié' toutes les chansons des beatles et à créé un morceau en s'en inspirant : c'était bien moche. Au moins, dans ce domaine, la machine, aussi 'artificiellement intelligente' soit-elle, est loin loin... loin derrière l'intelligence de l'âme et notre sensibilité. Mais peut-être est-ce juste expérimental ...
|
|
|
Dans Ada d'Antoine Bello (Gallimard, 2015), Ada, une machine, entreprend d'écrire des romans sentimentaux : ainsi sa première tentative Passion d'automne laisse dubitatif le détective chargé d'enquêter sur sa disparition (celle d'Ada). Sa conversation avec le concepteur (elle a eu accès à quelques grammaires, des dictionnaires et deux romans sentimentaux, Coup de foudre à Cape Cod et Douce comme la soie) offre une idée de sa performance :
"— Mark Twain, que je sache, n’écrivait pas : « Henry se méfiait du maréchal-ferrant, qui avait déjà cherché à l’empapaouter. »
— Simple erreur de registre, minimisa Weiss. Idem pour « Les nimbostratus gorgés d’humidité s’amoncelaient au-dessus de l’hacienda d’Edmund ».
— Je note aussi une curieuse tendresse pour les fonctions corporelles… Par exemple : « Edmund ponctua ses propos d’un rot retentissant qui fit trembler les murs et décoiffa Margaret. »
— Autres temps, autres mœurs…
— Ou encore : « Lord Arbuthnot souleva une fesse et lâcha une louise prodigieuse qui envoya un escadron de mouches au tapis. »
— Vous oubliez le meilleur, ajouta Dunn. « Il aimait les plaisirs simples de la vie : monter à cru, pêcher la truite et chier au fond des bois. »
Cette fois-ci, Weiss ne chercha pas d’excuse.
— Oui, c’est un problème. Ces derniers temps, Ada se complaît dans la grossièreté.
— Pourquoi, selon vous ?
— Difficile à dire. Nous lui avons fait lire des ouvrages analysant les ressorts de l’humour : le calembour, l’ironie, le comique de situation… Pour une raison qui m’échappe, elle ne semble avoir retenu que la scatologie.
— Vous ne pouvez pas la reprogrammer ?
— Si, bien sûr, mais nous risquerions d’altérer d’autres aspects de sa personnalité. C’est ce qui fait la richesse des machines apprenantes : vous ne pouvez jamais totalement prévoir la façon dont elles vont évoluer.
— Comment allez-vous rectifier le tir ?
— En expliquant à Ada que ce type d’humour n’a pas sa place dans un roman sentimental et qu’en s’obstinant à y recourir, elle compromet ses chances d’atteindre son objectif de vente.
— Encore que ! s’esclaffa Dunn.
— Vous avez raison, dit Frank. Passe encore que les hommes pètent et rotent mais l’héroïne doit conserver une certaine dignité.
— Entièrement d’accord. La fin de la scène de l’écurie discrédite à elle seule le reste du livre.
Frank lut à haute voix :
— « Henry l’aimait ! Margaret en avait désormais la preuve. Une vague de bonheur la submergea, si puissante qu’elle en fit dans sa culotte. “Ma chérie”, murmura le palefrenier en l’attirant par la taille. Elle se blottit en ronronnant contre le torse musclé de Henry, indifférente au ruisseau tiède qui courait le long de sa cuisse. »
|
|
|
Ada a juste reproduit une forme mesurée du Syndrome de Gilles de La Tourette.
Ceci ne nous dit toujours pas comment Elle à eu cette idée de Fou, ce sacrifice positionnel en g5!?
|
|
|
C'était un livre sympa, Ada. Je me rappelle avoir bien ri en lisant la liste des trois plaisirs simples de la comtesse :P
|
|
|
Finalement l être humain a encore de belles années de pousseur de bois devant lui.
Les strategies dynamiques employees par Alphazero me rappellent des joueurs comme rudolf spielmann ( son livre l art du sacrifice ) Les échecs "le jeu ou l esprit peut triompher de la matière".
Et je rejoins ce qui a été dit plus haut pour Mvl, c est a dire le fait qu on le voie régulièrement donner un pion pour l activité. Le plus dur a haut niveau étant de réussir a faire la différence, certains ont beau dire que Maxime a un répertoire limité il sait faire preuve de créativité dans ses idées. C est je trouve dans le même esprit que certaines parties jouees par Alpha zéro.
|
|
|
Comment peut-on parler d'un "flop"? Je ne parle même pas du résultat en lui même qui n'est pas si important mais des parties...
Des coups comme 31..Cg6, 47.Txc5, 21.Fg5, 19.Te1 suivi de 26.Dh1 et 30.Fxg6...c'est fantastique de voir qu'un logiciel est capable de les jouer...Je pense moi aussi que c'est sans doute un moment très important pour les Échecs...Mais pas mal de monde va y laisser des plumes c'est évident, ce qui explique certains avis circonspects et surtout effrayés sur chess.com ou sur Chessbase.com...
|
|
|
Fasciné par cette histoire et par les parties. Mais j'ai un certain nombre de bémols à apporter, moi aussi.
1) Incroyablement inéquitable de priver Stockfish de son arbre d'ouvertures alors que AlphaZero utilise lui ses connaissances acquises dans ce domaine dans les millions de parties qu'il a jouées.
2) Idem pour les tables de finale, AlphaZero c'est bien gentil son nom avec zéro connaissance mais ensuite il utilise ses connaissances acquises durant des millions de parties pendant qu'on ne permet pas à Stockfish d'utiliser les tables de finale. Totalement inéquitable.
3) On apprend que AlphaZero a joué avant leur match (?) 1300 (ou 1200) parties contre Stockfish. Sachant que AlphaZero apprend de ses parties précédentes, il a pu déceler des failles dans le jeu de Stockfish au cours de ces 1200 parties puis les exploiter durant leur match en 100 parties, contrairement à Stockfish. C'est totalement biaisé. Donc je serais intéressé de connaître le score des 100 premières parties entre les 2, sans affrontement préalable.
Je ne prétends évidemment pas que Stockfish aurait gagné le match, mais le minimim quand on organise un match c'est que les conditions soient équitables. Peut-être qu'il ne gagne alors pas sur un score si éloigné de celui du match Stockfish-Houdini de l'an dernier (environ 17-8).
Sinon quelqu'un comprend comment Stockfish peut jouer le coup Dh8 après 1 minute de réflexion ? Pas besoin d'anticiper le difficile Txc5 pour "comprendre" que ce coup est grotesque quand même, c'est la pire case du jeu pour la Dame.
Enfin quelqu'un a-t-il la moindre idée de comment AlphaZero réutilise ses connaissances pendant une partie ?!
|
|
|
C'est un peu ce que je disais hier à 17h30. L'auteur de Stockfish a déclaré :
The match results by themselves are not particularly meaningful because of the rather strange choice of time controls and Stockfish parameter settings: The games were played at a fixed time of 1 minute/move, which means that Stockfish has no use of its time management heuristics (lot of effort has been put into making Stockfish identify critical points in the game and decide when to spend some extra time on a move; at a fixed time per move, the strength will suffer significantly). The version of Stockfish used is one year old, was playing with far more search threads than has ever received any significant amount of testing, and had way too small hash tables for the number of threads. I believe the percentage of draws would have been much higher in a match with more normal conditions.
|
|
|
Oui, puisqu'il et si malin, AlphaZero n'a qu'à s'entraîner à gérer son temps sur 40 millions de parties puis jouer en conditions normales 1h30 + 30s par coup.
|
|
|
Il est sûr que les dix parties choisies donnent une vision déformée de sa performance, que les paramètres semblaient le favoriser... Mais pour traduire la performance de l'animal, il est probable qu'un match diffusé par les canaux habituels entre AlphaZero et Stockfish rassemblerait autant de spectateurs que le retour de Kasparov à Saint-Louis. Alors que le machin était inconnu il y a encore une semaine.
|
|
|
"L'auteur de Stockfish a déclaré..."
Hou le mauvais perdant !
|
|
|
Je signe pour un match en direct !
Pour une fois les gens regarderaient la partie et pas leur module.
|
|
|
Très juste, le module serait aux fraises de toute façon. Comme si on avait utilisé les ordis de l'époque pour analyser Spassky-Fischer.
|
|
|
J'étais surpris qu'on ait pas une "news" sur EE rapportant l'existence d'alpha-chess, mais on a, 2 jours après la sortie, un vrai article.
Merci ;)
|
|
|
En fait il semble, comme dans des parties par correspondance de haut niveau avain gain, très difgicile d'identifier l'erreur décisive. Je n'ai pas encore analysé les positions avec mon propre Stockfish mais il semble que contre AlphaZero il a constaté être perdant bien tard. La question vraiment intéressante c'est: à partir de quand AlphaChess "se sait" gagnant? Pourrait-t'il clairement identifier l'erreur décisive? Et entre 2 variantes nulles mais avec pièges profonds permettant un gain potentiel et un jeu plat dans l'autre, va-t'il faire comme l'humain: choisir la variante potentiellement gagnante? Si oui à toutes ces questions c'est une grosse révolution!
|
|
|
Erreur de sujet !!
|
|
|
@Arkhein : De ce que je comprends, AlphaZero a une fonction d'espérance : proba de gain + (proba de nulle /2) et il joue le coup qui maximise cette fonction. Ce qui explique pourquoi il répète les coups avant de changer, à la manière d'un humain. Il na va annoncer 100% de gain que quand le mat est forcé dans toutes les variantes.
Tout son apprentissage consiste à trouver les centaines de milliers voire millions de variables de cette fonction et leur associer les bons coefficients.
|
|
|
C'est le principe en effet. C'est pourquoi d'ailleurs si on disposait de alphazero, on n'aurait pas en sortie de module une fonction d'évaluation classique du style +1 correspond à un pion d'avance. On aurait plutôt une espérance de gain pour chaque coup envisagé. Par exemple au 1er coup 1.e4 = 0.52 ; 1.d4 = 0.54 ; 1.c4 = 0.53 ou un truc du style
Ce n'est ceci dit pas cela qui est absolument novateur chez alpha zero : il me semble que le concepteur de houdini associe aussi la fonction d'évaluation à la probabilité de gain à travers un calibrage ad hoc.
|
|
|
Quand on demande l'analyse sur chess24, on a aussi une barre exprimée en pourcentages pour gain, perte, et nulle.
|
|
|
Un GM m'a aussi confié qu'il jouait comme ça. Il regarde juste ce qui marche ! Une ligne est un peu moins bonne qu'une autre ? Pas de problème. Si elle affiche un pourcentage de réussite plus grand... il la joue ! Et ça marche, statistiquement, pour lui aussi ( d'après lui...).
|
|
|
Ce que je ne comprends pas c'est où a été stocké les connaissances de la phase d'autoapprentissage et si on sait, combien de GO ça représenterait!
|
|
|
@Brunico : la connaissance, c'est les poids des connexions entre neurones. Tu as un certain nombre de couches (layer) dans ton réseau de neurones. En général (feed forward), les neurones communiquent d'une couche donnée à la couche suivante, à travers les connexions neuronales ou synapses. Ce sont les poids de ces connexions qui emmagasinent l'information. Ces poids évoluent durant la phase d'apprentissage.
Tu as un exemple très simple ici, l'ancêtre du réseau de neurones (deux couches seulement !) :
https://fr.wikipedia.org/wiki/Perceptron
Quant au nombre de Go, il faudra attendre d'éventuelles précisions de DeepMind, cela dépénd principalement du nombre de connexions et donc de la taille du réseau.
|
|
|
@Brunico : Tout dépend de la nature de ces connaissances. Je doute qu'elles aient pour objectif de ressortir des coups préparés mais qu'au contraire elles permettent une meilleure compréhension du jeu et dans ce cas ce n'est pas nécessairement énorme en terme de volume de données, ni même en capacité de calcul.
|
|
|
Matthew Sadler analyse le style de jeu d'AlphaZero dans ses parties contre Stockfish. Voici comment on joue aux échecs au 21ème siècle!
Bold Sir Lancelot
Long-term sacrifice
Endgame class
Exactly how to attack
All-in defence
|
|
|
On reparle d'AlphaZero dans "La Méthode Scientifique" sur France Culture (à partir de 43:50).
|
|
|
Très bon travail des chargés de presse des maisons d'édition: il y a des bouquins qui sont ou vont sortir sur le sujet!
|
|
|
@chetmov, alphazero n'est qu'un sombre arriviste...
On pourra parler d'un bond de l'ia le jour où alphazero et ses compères discuteront des insondables mystères de la pensée humaine sur un poste voisin....
|
|
|
Je viens de regarder les parties que tu exposes ci-dessus.
Hallucinant.
Çà a l'air simple et on est presque content de voir les logiciel traditionnels à qui je n'ai pas arraché la moindre nulle depuis 2006 (date au pif, je dois pas être loin...) se prendre de telles déculottées.
On a l'impression que les logiciels classiques sont redevenus stupides.
C'est vraiment très étrange et j'aimerais bien voir Carlsen contre alphazero.
Est-ce que Stockfisch a joué autre chose que des Ouest-Indiennes ?
Où est-il possible de récupérer l'ensemble des pgn ?
|
|
|
Nulle part. Seules les parties à l'avantage d'Alpha 0 ont été publiées.
|
|
|
Alphazero a joué un autre match contre Stockfish 8 en janvier 2018.
La cadence était de 3h par partie et 15s/cp.
Stockfish utilisait 44 cores, 32 GB de Ram et les tables de finales "Syzygy"
Alphazero tournait avec 4 TPU et 44 cores.
Alphazero a gagné (+155 -6 =839).
Des parties sont disponibles ici :
https://deepmind.com/research/alphago/alphazero-resources/
Il y a des articles sur ce match et des parties que l'on peut rejouer mais ce sont des sites concurrents alors pour ne pas me faire hacher menu je ne les poste pas.
|
|
|
Merci les amis
|
|
|


